Comments (12)
 lucabergamini
commented on April 28, 2024
1
lucabergamini
commented on April 28, 2024
1
I completely forgot it, that makes a lot of sense :)
Yeah that could explains it all...unfortunately autograd is used only in Pytorch as far as i know, so we can't just compile the same network under TF to check if the graphs match. Thank you in advance anyway, I'll try to look at the code behind in my spare time :)
from tensorboardx.
 miguelvr
commented on April 28, 2024
1
miguelvr
commented on April 28, 2024
1
I think the activations should be outside if you define them outside, anyway! By doing that the graph would be much cleaner
from tensorboardx.
 lanpa
commented on April 28, 2024
lanpa
commented on April 28, 2024
I tried the following code
import torch
import torch.nn as nn
from torch.autograd.variable import Variable
import torch.nn.functional as F
from collections import OrderedDict
from tensorboard import SummaryWriter
class M(nn.Module):
def __init__(self):
super().__init__()
self.conv_0 = nn.Conv2d(1,1,3)
self.conv_1 = nn.Conv2d(1,1,3)
self.conv_r1 = nn.Conv2d(1,1,5)
self.fc1 = nn.Linear(2,1)
self.fc2 = nn.Linear(1,1)
def forward(self,i):
# i stand as the input
# conv_j is a module
x = self.conv_0(i)
x = self.conv_1(x)
y = self.conv_r1(i)
z = torch.cat((y,x),1)
z = z.view(len(z),-1)
z = self.fc1(z)
z = F.relu(z)
z = self.fc2(z)
z = F.log_softmax(z)
return z
writer = SummaryWriter('runbug')
m = M()
z = m(Variable(torch.Tensor(1,1,5,5), requires_grad=True))
writer.add_graph(m, z)
writer.close()The result seems correct, can you provide a runnable code to reproduce the first graph?
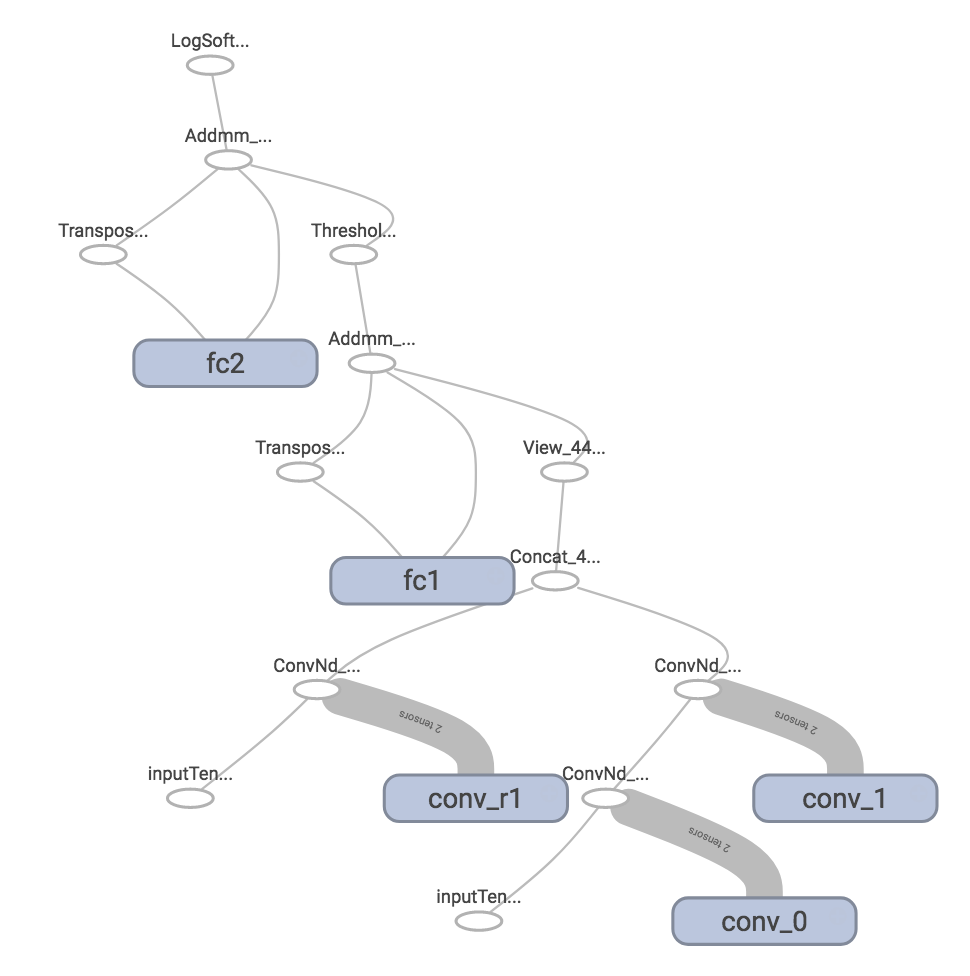
As for defining scope for modules, it needs to retrieve the module name associated with certain function object. I will look into it in the future.
from tensorboardx.
lucabergamini
commented on April 28, 2024
Using your code everything works fine, but if you introduce ReLU and MaxPooling you get this:
import torch
import torch.nn as nn
from torch.autograd.variable import Variable
import torch.nn.functional as F
from collections import OrderedDict
from tensorboard import SummaryWriter
from datetime import datetime
class M(nn.Module):
def __init__(self):
super(M,self).__init__()
self.conv_0 = nn.Conv2d(1,1,3)
self.conv_1 = nn.Conv2d(1,1,3)
self.conv_r1 = nn.Conv2d(1,1,5)
self.fc1 = nn.Linear(2,1)
self.fc2 = nn.Linear(1,1)
def forward(self,i):
# i stand as the input
# conv_j is a module
x = self.conv_0(i)
x = F.relu(x)
x = F.max_pool2d(x,1)
x = self.conv_1(x)
x = F.relu(x)
x = F.max_pool2d(x,1)
y = self.conv_r1(i)
y = F.relu(y)
y = F.max_pool2d(y,1)
z = torch.cat((x,y),1)
z = z.view(len(z),-1)
z = self.fc1(z)
z = F.relu(z)
z = self.fc2(z)
z = F.log_softmax(z)
return z
writer = SummaryWriter('runs/'+datetime.now().strftime('%B%d %H:%M:%S'))
m = M()
z = m(Variable(torch.Tensor(1,1,5,5), requires_grad=True))
writer.add_graph(m, z)
writer.close()
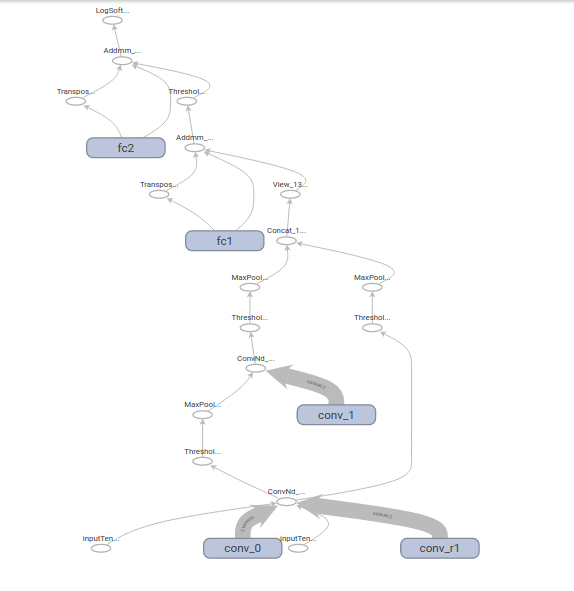
from tensorboardx.
lanpa
commented on April 28, 2024
OK, I just found a more compact network to reproduce strange output:
class M(nn.Module):
def __init__(self):
super(M,self).__init__()
self.conv_x1 = nn.Conv2d(1,1,3)
self.conv_x2 = nn.Conv2d(1,1,4)
self.conv_y = nn.Conv2d(1,1,6)
def forward(self,i):
x = self.conv_x1(i)
x = self.conv_x2(x)
x = F.relu(x)
y = self.conv_y(i)
y = F.relu(y)
z = torch.cat((x,y),1)
return zfrom tensorboardx.
lucabergamini
commented on April 28, 2024
As far as i can see your network seems fine to me.
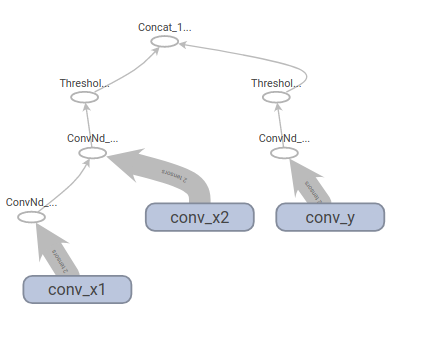
However, changing to this:
class M(nn.Module):
def __init__(self):
super(M,self).__init__()
self.conv_x1 = nn.Conv2d(1,1,3)
self.conv_x2 = nn.Conv2d(1,1,4)
self.conv_y = nn.Conv2d(1,1,6)
def forward(self,i):
x = self.conv_x1(i)
x = F.relu(x)
x = self.conv_x2(x)
x = F.relu(x)
y = self.conv_y(i)
y = F.relu(y)
y = F.max_pool2d(y,1)
z = torch.cat((x,y),1)
return z
Leads to strange behaviours.

P.S. I'm a bit puzzled about the input tensors, sometimes I can't get them rendered (as in this last figure).
from tensorboardx.
lanpa
commented on April 28, 2024
Did you set requires_grad=True for the input variable?
btw, the graph drawing is based on autograd's back-propagation graph, I am wondering whether autograd uses internal optimizations to speed up the computation and causes this behavior. Anyway, I will look into it later :)
from tensorboardx.
miguelvr
commented on April 28, 2024
is it possible to keep the module operations inside the layer block (scope)? Right now it only seems to associate weights with the scope, but it would be nice to assign the module's forward operations to the scope as well
from tensorboardx.
lucabergamini
commented on April 28, 2024
You mean to have every layers inside a user-defined module inside a single block with the name od the module?
from tensorboardx.
miguelvr
commented on April 28, 2024
no, I meant the operations related to a given nn.Module being inside that module's scope.
If you add a graph for 2 linear layers you get 2 scopes one for each, containing only the weight and bias variables while the operations over theses variables are shown outside the scope.
It would be nice to have operations like the addmm for the linear to be positioned within the scope of it's module. The same applies to the examples above with the ConvNd and Threshold operations that appear outside the scope of the convolutional layers
from tensorboardx.
lucabergamini
commented on April 28, 2024
For the ```addmul`` case it should be easy to implement, because in fact the operation lies in the same module (the Linear one), while for the the threshold (AKA ReLU , Sigmoid, etc) I'm not quite sure since it has its own module (which you usually add in forward using F.relu() as example), so I think we need the equivalent of the scope from TF.
from tensorboardx.
lanpa
commented on April 28, 2024
The name of variable comes from
https://github.com/lanpa/tensorboard-pytorch/blob/master/tensorboard/graph.py#L36
However there seem no similar trick to extract that information from autograd's graph. I think the reason is that it's a pretty low level operation, object's name is not important.
The good news is there is a ongoing work that makes trace possible. Once confirmed success, it should be easy to draw a pretty graph. My guess XD
from tensorboardx.
Related Issues (20)
- tensorboardX is incompatible with protobuf 4.21.0 HOT 16
- draw NaN with triangle
- Subsequent hparams missing HOT 4
- DeprecationWarning: crc32c.crc32 will be eventually removed, use crc32c.crc32c instead HOT 2
- AttributeError: 'NoneType' object has no attribute 'get_logdir' HOT 3
- Protobuf version HOT 4
- How can I connect previous log file into new one in tensorboard HOT 1
- How can i read tensorboard by python ? HOT 2
- Deprecation Warnings HOT 15
- OSS License compatibility question
- Remove upper pins on protobuf HOT 4
- tensorboardX is converting white/blank space and other non alphanumeric characters to underscore
- Update unittests for newer protobuf
- Possibility of v2.5.2 with upper pin on protobuf of <4? HOT 3
- The license_file parameter is deprecated HOT 3
- Loosening protobuf version limit breaking downstream packages HOT 7
- Is there an efficient way to log line plots? HOT 5
- EOFError multiprocessing HOT 1
- Set experiment name when using CometML HOT 1
- Support add_mesh for visdom writer?
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from tensorboardx.