Comments (6)
 GuillaumeConnan
commented on June 12, 2024
2
GuillaumeConnan
commented on June 12, 2024
2
We are experiencing the exact same behavior, with more than 50M existing metrics and ~500k daily new metrics due to ephemeral container or instance IDs in the metric name.
Without index pruning, MT heap uses like 250GB of RAM per instance and keeps growing as new metrics are created, which is not suitable in the long term.
On the other side, with index pruning activated, MT heap tends to stabilize, but old metrics can no longer be rendered even if the data is still present in the backend.
Is there a way to more rely on the backend to lower memory usage, even if it would degrade (maybe not so much?) requests performances?
from metrictank.
 deniszh
commented on June 12, 2024
deniszh
commented on June 12, 2024
Another Metrictank user here. It's definitely memory hog. Also, IMO Metrictank it's not really designed to work as standalone application. E.g. during restart you will loose access to metrics until replay from Kafka would not be finished - so, you need at least pair of instances. It's designed to be used in cluster installations with orchestrated control. In our case if we see number of metrics increasing (which cause memory pressure) we're just increasing number of nodes and doing rolling restart.
Also, sharing single node between services is clearly antipattern.
In my opinion if you do not want to use clustering software try:
- go-carbon + carbonapi - hardly scalable but OK for single node - see e.g. https://github.com/go-graphite/docker-go-graphite for config example. Also, do not support tags.
- Graphite-clickhouse - it's bit more complex, require Clickhouse installation - example is https://github.com/lomik/graphite-clickhouse-tldr
- Victoriametrics + carbonapi - less tested, example is in https://github.com/deniszh/graphite-victoriametrics-tldr (VM has built-in Graphite compatibility but in Enterprise version only).
from metrictank.
 shanson7
commented on June 12, 2024
shanson7
commented on June 12, 2024
If you look at the "metrics active" it seems like there are new series being indexed regularly. You might need to set up pruning in index-rules config to trim off stale series (e.g. not seen in 3 days). This will make those series unquery-able so make sure it's set appropriately.
Also, I agree with @deniszh about running a single instance. MT is meant to scale ingest linearly, so partitioning across multiple instances is the way to grow.
from metrictank.
 thmour
commented on June 12, 2024
thmour
commented on June 12, 2024
@deniszh We already use go-carbon + whisperdb and it has already reached its limits, 99% disk util and we can't run interesting queries without timeouts. I tried to change to metrictank with a single node setup in a 32CPU+60GB ram machine but it looks like the memory is constantly increasing whatever I try to do. I will start using a double instance so at least it ping pongs betweens those two?
@shanson7 thanks for the insight, there is one subgroup of metrics that is currently at 8.9M. I guess I will need to start pruning it.
from metrictank.
thmour
commented on June 12, 2024
I moved the metrictank instance now to a new VM with 60GB of RAM, so it doesn't have to run with scylladb anymore, prune metrics inactive older than a week, and from 10M active metrics I went down to 4M. Now metrictank uses suddenly a lot of memory and does nothing (no render, no metrics ingest) at 50% of memory usage. Does this have to do that a lot of requests (20K packets per minute with various amount of metrics) go to the carbon input of metrictank?
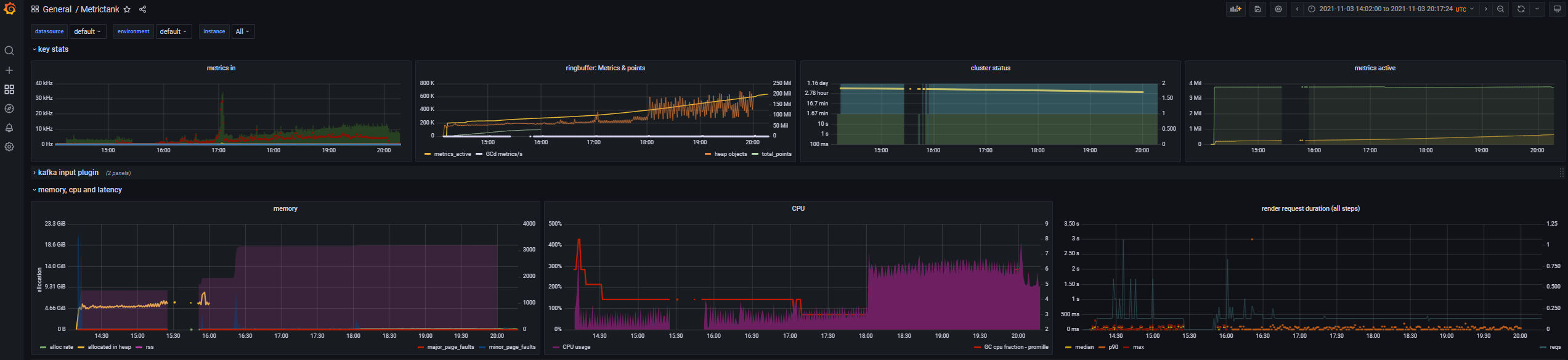
from metrictank.
 stale
commented on June 12, 2024
stale
commented on June 12, 2024
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
from metrictank.
Related Issues (20)
- High priority / backlog on metric flush HOT 5
- MT-Whisper-Importer-Writer can get stuck on invalid requests HOT 1
- request: tag-native divide and asPercent functions HOT 9
- Panic and crash in chunk cache
- Graphite API responds with 413 when response is too large not request HOT 5
- Add more logging with traceID HOT 2
- Ability to "revive" archived series HOT 15
- Support "archive" in tags/delByQuery HOT 2
- Stored 'lastupdate' being approximate can cause inconsistent missing data HOT 6
- deletes don't affect stale metrics. They may resurface if max-stale gets increased HOT 2
- Move to go modules for dependency management HOT 5
- Authentication in mt-gateway or document other way to proceed without tsdb-gw HOT 4
- Panic in mt-whisper-importer-reader HOT 1
- Conf parsing changes fail to parse regex HOT 2
- Multiple shards on same hardware node HOT 2
- UnpartitionedMemoryIdx.Get does not check writeQueue
- MetricData messages in mdm topic poorly defined. make versioning explicit?
- Is the project stalled? HOT 2
- Control partition size using Cassandra as backend HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from metrictank.