Comments (6)
 kingwayliang
commented on April 28, 2024
1
kingwayliang
commented on April 28, 2024
1
After more experimentation, we found:
-
having a max number of training steps 2x to 2.5x of the number of collected episodes gives the best training result.
-
The grasping environment selects random objects to spawn the first time the environment runs setup and doesn't re-select after. So if episodes are collected on small number of CPU's, the environment should be tweaked to re-select objects by calling _get_random_objects to ensure episodes cover a diverse set of objects.
-
The urdf_pattern defined in _get_random_objects for training object did not work properly on our machine and only picked out 100 objects. Changing [^0] to [!0] solved the problem for us.
With the above fixes we were able to reproduce results similar to those in the paper.
from google-research.
 ericjang
commented on April 28, 2024
ericjang
commented on April 28, 2024
Good performance results (for both on/off-policy) require seeding the training with quite a bit of data collected with the random policy before training. Try collecting at least 100k episodes of random policy first (it is really important to run this collection in parallel on a CPU cluster, otherwise gathering this data takes a long time).
from google-research.
 andreykurenkov
commented on April 28, 2024
andreykurenkov
commented on April 28, 2024
@ericjang continuing discussion here as per email.
After collecting 100k grasps as you suggested , we got ~0.55 final test perf for both on and off policy. We are hoping to match the results in your paper of ~0.7 & ~0.8 performance for off and on policy respectively.
We don't have infra to distribute over many CPUs, so would rather not try with 1M - since your provide results for 100k it seems fine to try and replicate those. We don't modify any other aspects of the configs in the repo. Could you suggest any other things to try or check to get replication working?
from google-research.
ericjang
commented on April 28, 2024
We re-ran our Q-learning experiments with replicated trials on P100 gpus - here's a screenshot of the tensorboard.

To be honest I haven't run this code in a non-Google environment (e.g. on GCP / AWS), perhaps a difference could arise from there. One other thing to try - when gathering 100k episodes, we distribute across 1000 different collect workers, each which resets with a different random seed.
from google-research.
andreykurenkov
commented on April 28, 2024
Are all the different lines different runs? The variance looks to be pretty high (at a glance, higher than as shown in paper, though ofc hard to tell), your lowest outcome (orange) is close to our outcome.
We will try scaling data collection to just 10 CPUs + running a few times, see what we get.
from google-research.
kingwayliang
commented on April 28, 2024
We re-collected 100k episodes using 8 CPUs and re-trained with on-policy, got the results below.


Both eval and test rewards peaked at 250~300k training steps but subsequently decreased to values similar to our previous results. @ericjang the re-ran results you posted show training with 200k steps, while we've been training with the default 2M steps, can this be the problem? It seems strange the policy would get worse after more training steps.
We also re-trained off-policy using the new episodes and only for 200k steps, with the following results. Test reward is still relatively low.

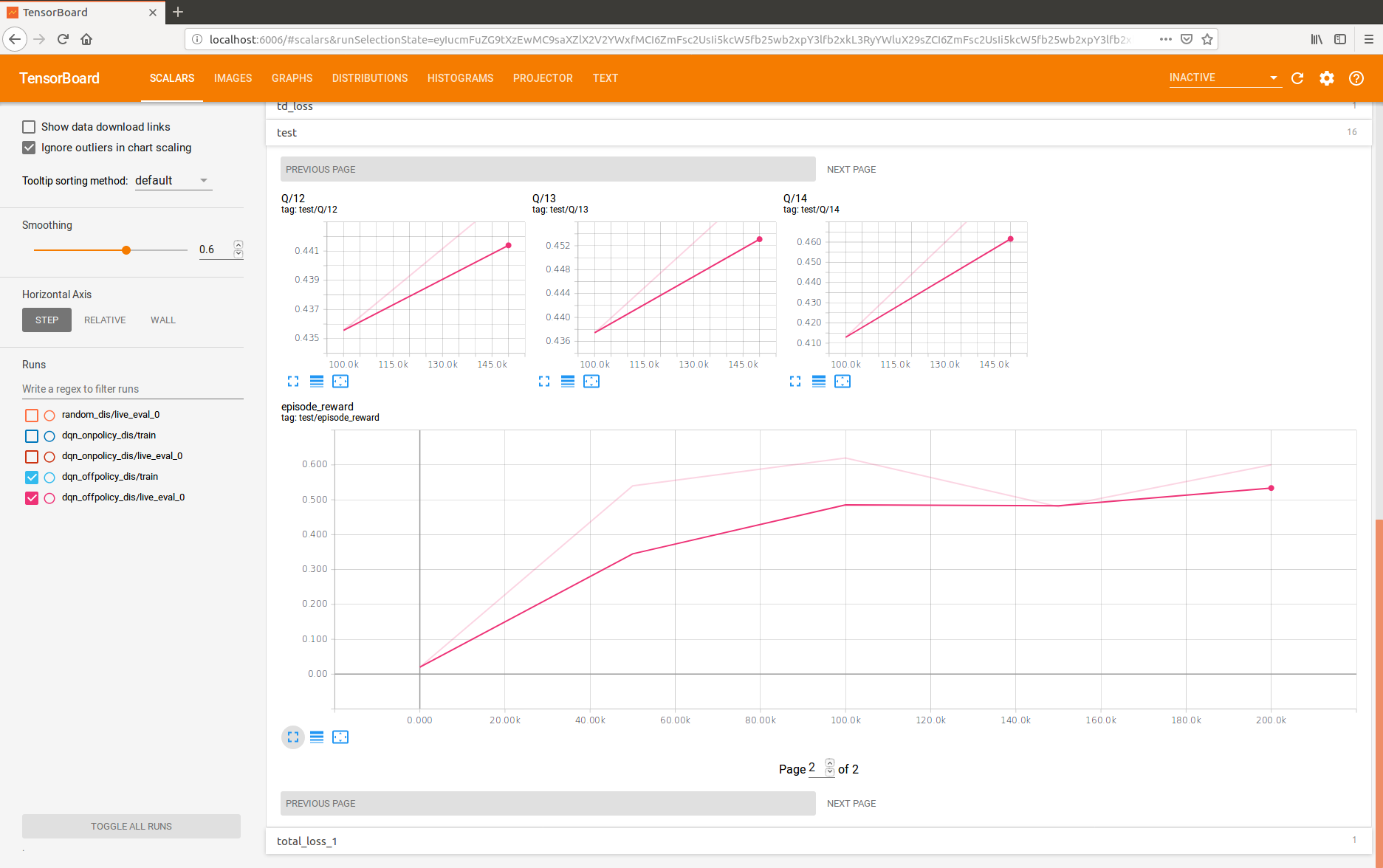
from google-research.
Related Issues (20)
- tsmixer_extended HOT 2
- irregular time series
- Bias Racial Output from Google's AI powered Search Labs
- Automl run_demo.sh build error HOT 1
- Buscador HOT 1
- Unable to train with GPU
- ModuleNotFoundError: No module named 'cubert' HOT 1
- How to add datasets in VATT?
- H HOT 2
- Big issue in UFlow code - dataset and train_it
- Possible normalization error in Gram-Schmidt orthonormalization process in GPNR
- bug in VRDU evalution code HOT 2
- [SMURF] Port Weights to PyTorch HOT 3
- Google HOT 2
- datasets HOT 5
- J
- [DITO] About train*.tfrecord and val*.tfrecord file HOT 1
- TiDE model loading errors
- [FindIt] Facing issues in running findit.demo
- Is SayCan code in the repo still working?
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from google-research.