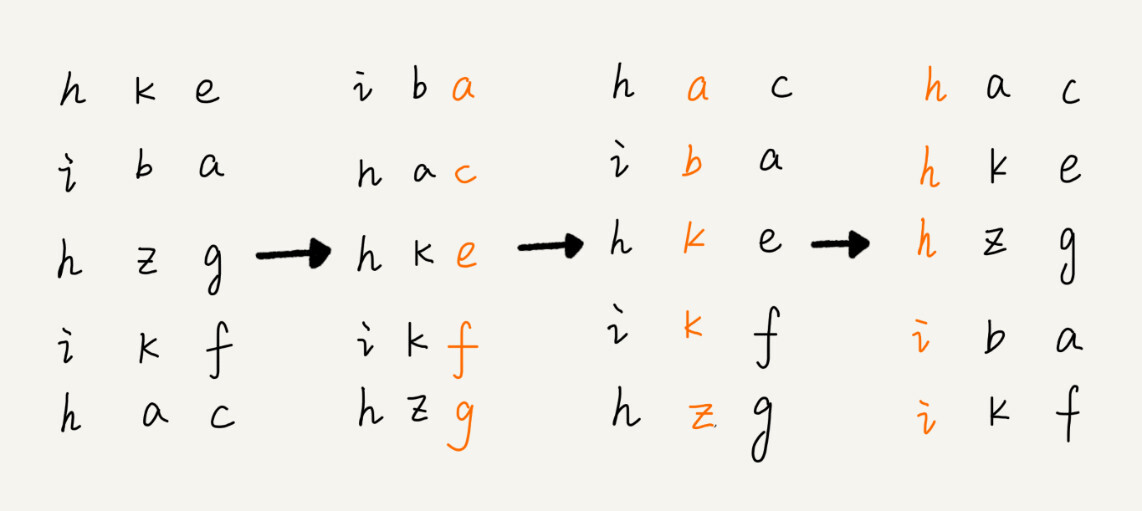fridas / blog Goto Github PK
View Code? Open in Web Editor NEW学习总结
学习总结

















2018年07月12日
用过vue-router、vue-touch的同学都知道插件的便利。插件功能非常强大,不只局限于mixin、directive,其范围是没有限制的,你可以用插件来添加包括但不限于以下几种:
Vue的插件需要提供一个公开方法install,它相当于插件的注册或声明、会在我们使用(Vue.use(MyPlugin))该插件时被调用。install接受两个参数,第一个参数是Vue构造器,第二个参数是可选的选项对象(使用插件时传入)。
MyPlugin.install = function (Vue, options) {
// 1. 添加全局方法或属性
Vue.myGlobalMethod = function () {
// 逻辑...
}
// 2. 添加全局资源
Vue.directive('my-directive', {
bind (el, binding, vnode, oldVnode) {
// 逻辑...
}
...
})
// 3. 注入组件
Vue.mixin({
created: function () {
// 逻辑...
}
...
})
// 4. 添加实例方法
Vue.prototype.$myMethod = function (methodOptions) {
// 逻辑...
}
}官网对vue插件有详细的介绍。
下面我们对用插件添加全局方法或属性、添加全局资源、注入组件、添加实例方法分别进行实践。
全局方法
// plugin.js
let Plugin = {}
Plugin.install = (Vue, options) => {
// 全局方法
Vue.addition = (...args) => {
let result = 0
args.forEach(item => {
result += Number(item)
})
return result
}
}
export default Plugin使用:
<el-input v-model="add1"></el-input>
+
<el-input v-model="add2"></el-input>
=
<span>{{addResult}}</span>
<el-button @click="add">计算</el-button>
import Vue from 'vue'
export default{
data () {
return {
add1: '',
add2: '',
addResult: ''
}
},
methods: {
add () {
this.addResult = Vue.addition(this.add1, this.add2)
}
}
}结果:
全局属性
// plugin.js
let Plugin = {}
Plugin.install = (Vue, options) => {
// 全局属性
Vue.commonDomain = '//community.kaola.com'
}
export default Plugin使用:
import Vue from 'vue'
export default {
created () {
console.log(Vue.commonDomain)
}
}结果:
指令
// plugin.js
let Plugin = {}
Plugin.install = (Vue, options) => {
// 全局指令
Vue.directive('smile', {
bind (el, binding, vnode, oldVnode) {
el.className = 'smile'
}
})
}
export default Plugin使用:
.smile{
display: inline-block;
width: 50px;
height: 50px;
background: url('http://bpic.588ku.com/element_pic/18/03/28/0b9caa6e61af8d7b83b62dd96a38494c.jpg');
background-size: 100%;
}<span v-smile></span>结果:
另外可以参考:按字节限制输入框输入长度
过滤器
// plugin.js
let Plugin = {}
Plugin.install = (Vue, options) => {
// 全局过滤器
Vue.filter('yuanSuffix', (val) => {
return val + '元'
})
}
export default Plugin使用:
金额:{{ amount | yuanSuffix }}
export default{
data () {
return {
amount: '100'
}
}
}结果:
// plugin.js
let Plugin = {}
Plugin.install = (Vue, options) => {
// 全局mixin
Vue.mixin({
methods: {
hello () {
console.log('hello world')
}
}
})
}
export default Plugin使用:
export default{
created () {
this.hello()
}
}结果:
// plugin.js
let Plugin = {}
Plugin.install = (Vue, options) => {
// 添加Vue实例方法-常量
Vue.prototype.$commonDomain = '//community.kaola.com',
// 添加Vue实例方法-方法,类型判断
Vue.prototype.$typeOf = (o) => {
return o == null ? String(o) : ({}).toString.call(o).slice(8, -1).toLowerCase()
},
// 添加Vue实例方法-方法,深克隆
Vue.prototype.$clone = (obj) => {
var type = Vue.prototype.$typeOf(obj)
switch (type) {
case 'object':
var cloned = {}
for (var i in obj) {
cloned[i] = Vue.prototype.$clone(obj[i])
}
return cloned
case 'array':
return obj.map(Vue.prototype.$clone)
default:
return obj
}
}
}
export default Plugin使用:
export default{
data () {
return {
originObj: {
a: [1, 2, 3],
b: false,
c: {
d: [4, {e: 'eee'}],
f: '2018-07-12'
},
g: null
}
}
},
created () {
console.log(this.$commonDomain)
console.log(this.$typeOf(this.originObj))
let cloneObj = this.$clone(this.originObj)
console.log(cloneObj)
console.log(cloneObj === this.originObj)
}
}结果:
看到这里,有同学可能疑惑,插件公开方法install接受两个参数——Vue构造器 和 可选的选项对象,上述的所有例子都只用到了Vue构造器、而没有用到选项对象这个参数,那么这个参数是如何传入的、怎么使用的呢?
// 使用插件
import MyPlugin from './plugin.js'
Vue.use(MyPlugin, { // 传入选项对象参数
name: 'Frida'
})// plugin.js
let Plugin = {}
Plugin.install = (Vue, options) => {
let name = options.name
// 全局mixin
Vue.mixin({
methods: {
hello () {
console.log('hello', name)
}
}
})
}
export default Plugin使用:
export default{
created () {
this.hello()
}
}结果:
vue插件功能强大、使用方便,可以极大提高开发效率和开发体验。
主要是记录工作学习过程中遇到的CSS问题,以供以后回顾查看。
需求:input输入框placeholder文字颜色和输入的文字颜色不同
解决:
参考:https://stackoverflow.com/questions/2610497/change-an-html5-inputs-placeholder-color-with-css
需求:文本溢出显示省略号(...)
解决:
max-width:100px; //需要设置宽度或者最大宽度
overflow:hidden;
text-overflow:ellipsis;
white-space: nowrap;
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 3; // 显示行数
overflow: hidden;
text-overflow:ellipsis;
border-style设为dashed或dotted时的虚线间距无法改变,用背景图片来模拟
background-image: linear-gradient(to right, #ddd 0%, #ddd 50%, transparent 50%);
background-size: 11px 1px;
background-repeat: repeat-x;
对比用border-style:
border-bottom: 1px dashed #ddd;
用CSS实现三角形。
.triangle {
width: 0;
height: 0;
border-width: 50px;
border-style: solid;
border-color: blue transparent transparent transparent;
}我们可以通过border-width来设置4面边框的长度、从而改变三角形各边长;通过border-style来设置不同图形(比如扇形);通过border-color来设置三角形朝向(上下左右4面三角形)。
.triangle {
width: 0;
height: 0;
border-width: 50px 20px 60px 70px;
border-style: solid;
border-color: transparent transparent red transparent;
}从下图可以看到border-width设置情况:
参考:
2019年03月16日
二分查找也叫折半查找,它是针对一个有序的数据结合,每次通过跟区间中间元素进行比较,将待查找区间缩小一半,直到找到要查找的那个元素、或者查找区间缩小为0为止。
二分查找是一种非常高效的查找算法,来分析下其时间复杂度。
假设数据大小是n,每次查找后要查找的数据都变为之前的一半,所以我们每次要查找的数据量分别是:
n;
n/2;
n/4;
n/8;
...
n/(2^k)
...
当n/(2^k) = 1时,k就是区间减半的次数。而每次区间减半只涉及两个数据的大小比较(目标元素与中间元素的比较)。我们知道,讨论时间复杂度,就是看最基本的操作进行的次数,区间减半进行了k次、那么比较操作就进行了k次,所以时间复杂度是:
O(k) = O(log2(n)) = O(logn)。
// 基本二分查找——迭代
function binarySearch(array, value) {
let low = 0,
high = array.length - 1;
while (low <= high) {
let mid = low + ((high - low)>>1);
if (array[mid] == value) {
return mid;
} else if (array[mid] < value) {
// 如果中间元素小于目标元素,那么目标元素在右边区间
low = mid + 1;
} else {
// 如果中间元素大于目标元素,那么目标元素在左边区间
high = mid - 1;
}
}
return -1;
}注意点:
// 基本二分查找——递归
function binarySort(array, value) {
return recursive(array, 0, array.length-1, value);
}
function recursive(array, low, high, value) {
if (low > high) {
return -1;
}
let mid = low + ((high - low) >> 1);
if (array[mid] == value) {
return mid;
} else if (array[mid] < value) {
return recursive(array, mid+1, high, value);
} else {
return recursive(array, low, mid-1, value);
}
}// 二分查找变形——查找第一个值等于给定值的元素
function binarySort1(array, value) {
let low = 0,
high = array.length - 1;
while (low <= high) {
let mid = low + ((high - low) >> 1);
if (array[mid] < value) {
low = mid + 1;
} else if (array[mid] > value) {
high = mid - 1;
} else {
// 当array[mid]等于value时,我们不知道它是否是第一个值为value的元素。1)如果mid等于0,那它肯定是第一个元素;2)如果array[mid-1]不等于value,那array[mid]就是第一个值为value的元素;3)如果mid不是第一位且它前面还有值为value的元素,那么我们将查找区间锁定在[low, mid-1]。
if ((mid == 0) || (array[mid - 1] !== value)) {
return mid;
} else {
high = mid - 1;
}
}
}
return -1;
}// 二分查找变形——查找最后一个值等于给定值的元素
function binarySort2(array, value) {
let low = 0,
high = array.length - 1;
while (low <= high) {
let mid = low + ((high - low)>>1);
if (array[mid] < value) {
low = mid + 1;
} else if (array[mid] > value) {
high = mid - 1;
} else {
if ((mid == array.length-1) || array[mid+1]!== value) {
return mid;
} else {
low = mid + 1;
}
}
}
return -1;
}// 二分查找变形——查找最后一个值等于给定值的元素
function binarySort3(array, value) {
let low = 0,
high = array.length - 1;
while (low <= high) {
let mid = low + ((high - low)>>1);
if (array[mid] < value) {
low = mid + 1;
} else {
if ((mid == 0) || array[mid-1]<value) {
return mid;
} else {
high = mid + 1;
}
}
}
return -1;
}// 二分查找变形——查找最后一个值等于给定值的元素
function binarySort4(array, value) {
let low = 0,
high = array.length - 1;
while (low <= high) {
let mid = low + ((high - low) >> 1);
if (array[mid] > value) {
high = mid - 1;
} else {
if ((mid == array.length-1) || array[mid+1]>value){
return mid;
} else {
low = mid + 1;
}
}
}
return -1;
}在Vue官方文档里,有这样一段内容:
由于JavaScript的限制,Vue不能检测以下变动的数组:
为了解决第一类问题,以下两种方式都可以实现和 vm.items[indexOfItem] = newValue 相同的效果,同时也能触发状态更新:
// Vue.set
Vue.set(example1.items, indexOfItem, newValue)
// Array.prototype.splice
example1.items.splice(indexOfItem, 1, newValue)
为了解决第二类问题,可以使用 splice:
example1.items.splice(newLength, 0, undefined)
其中Array.splice( )方法用于从一个数组中移除元素,如有必要,在所移除元素的位置上插入新元素,并返回所移除的元素,而原数组被改变。
其语法为:
arrayObject.splice(index, howmany, [item1[,item2[,…[,itemN]]]])
所以上面的第二个方法(Array.prototype.splice)在example1里添加了新值newValue,并改变了example1本身。【Vue重新封装了包括Array.prototype.splice在内的许多数组方法,这些方法会把数据属性转换为访问器属性】
对于对象,还可以用Object.assign( )浅拷贝一个对象来解决(替换掉vm.data的原对象):
vm.user = Object.assign({}, vm.user, {age: 18, name: ’zoro'})
那么为什么直接对数组(或对象)利用索引进行设值、直接更改length时不会触发状态更新呢?Vue官方文档只说“由于JavaScript的限制”,那么这个限制到底是什么呢?
Vue监听数据变动,是利用了JavaScript的Object.definedProperty方法,依靠descriptor里的getter和setter这两个访问器属性。【关于访问器属性可以参考https://github.com/FridaS/blog/issues/7】(Vue不支持IE8以下浏览器是因为IE8以下浏览器不支持Object.definedProperty)
即 new Vue(obj) 时,其内部发生了大体如下的代码转换(将数据属性,转换为了访问器属性):
function Vue (obj) {
obj.data.keys().forEach((item, index) => {
Object.defineProperty(obj.data, item, {
set () {
// 可以在此处进行事件监听
},
get () {
//
}
})
})
return obj;
}
所以当使用索引给数组或对象添加属性(如 vm.items[0] = {})时,是直接 = 赋值,是数据数据属性的(而不是访问器属性),是默认的[[Get]]操作和[[Put]]操作,所以无法检测变动。
至于push等操作可以检测到变动,是因为Vue把这些Api重新封装了。
参考:
前两天腹肌哥哥抱怨我们的样式文件杂乱而难以维护时提到了BEM,于是决定对其一窥究竟。
BEM自称前端开发方法论(Frontend Development Methodology),提供了包括命名规则、CSS/JS模块化原则、构建工具在内的一套用于开发环节的方法。这篇文章只讨论其在CSS class name命名上的规范。
按照BEM的官方说明,
BEM是一种非常有用的、强大的、简单的命名规范,它使你的前端代码具有更高的可读性、更易于使用、更容易扩展、更健壮、更明确、更严格。
BEM代表 块(block)、元素(element)、修饰符(modifier),它们被称为BEM实体。
块是本身具有意义的独立实体。在大多数情况下,任何独立的页面元素都可以被视作一个块。比如header、container、menu、checkbox、input。
块可以包含其他块。比如,下图中的header块包含了logo块、navigation块和search块。
比快更细粒度的是元素(element)。
元素是块的组成部分,它表现为某一特定的功能。元素依赖块而存在、它只在其所属的块的上下文中有意义(脱离块就不能使用)。比如menu块的item元素、header块的title元素。
下图中,一个search块包括text input元素和search button元素。
一个“修饰符”可以理解为一个块或一个元素的特定状态,我们使用它来定义块或元素的不同的外观及行为。
举个例子来理解下:一个button块有两种颜色:红色和绿色,那么就可以定义两个修饰符:red和green,得到的完整的class name就是button--red和 button--green。
BEM方法论提出者Yandex的命名规则:
property-editor;menu,该快中的元素的CSS类名都会包含menu作为前缀;menu__item;menu__item_selected,其中selected是不二修饰符;名值对修饰符由名称和值两部分组成,通过单个下划线(_)分隔,如order_status_paid对应 status 为 paid 的订单;BEM并没有限定必须使用怎样的命名规则,目前比较流行的是由Harry Roberts提出的命名规范(也是Google的Material Design Lite库使用的命名规则),其与Yandex规则的不同之处有:

<ul class="menu">
<li class="menu__item menu__item--selected">Menu Item 1</li>
<li class="menu__item">Menu Item 2</li>
<li class="menu__item">Menu Item 3</li>
</ul>.menu{
list-style: none;
}
.menu__item{
font-weight: bold;
}
.menu__item--selected{
color:red;
}BEM的优点:
BEM特色的关键是块的相互独立,具有高度的可移植性和可复用性;
在BEM命名规则中,所有的CSS样式规则都只用一个类别选择器,因此所有样式规则的特异性(specificity)都是相同的,也就不存在复杂的优先级问题;
防止CSS嵌套过深;
每个CSS类名都很简单明了,可读性非常高;
类名的层次关系可以与DOM节点的树形结构相对应,读HTML结构时,能很容易地看出元素之间的依赖关系;
减少了类名冲突和副作用的可能性,没有如.mod-xxx ul li 的写法带来的潜在的嵌套风险。
我在haitaowap工程上随意找了一段代码:
其样式为:
现在按照BEM改写它:
<div class="n-inGroupBuyShare">
<ul class="dialogs">
<li class="product">
<div class="head">
<img class="head__img" src="${headImg!''}" alt="">
</div>
<div class="content">
<img class="content__img" src="${imageUrl!''}" alt="">
<p class="content__desc">${goodsTitle}</p>
<p class="content__price">¥<em class="content__actual-price">${groupBuyPrice}</em></p>
</div>
</li>
</ul>
</div>.head__img, .content__img{
width: 444px;height: 446px;
}
.content__desc{
margin-top: 7px;margin-bottom: 9px;height: 111px;overflow: hidden;
font-size: 26px;line-height: 37px;font-weight: bold;
}
.content__price{
display: flex;
height: 50px; align-items:center;
font-size: 28px;color: #e31436;
}
.content__actual-price{
margin-left:-4px;
font-size:52px;font-style:italic;margin-top:-13px;
letter-spacing:1px;font-weight:bold;
-webkit-font-smoothing: antialiased;text-rendering: optimizeLegibility;
}当然,有很多人不喜欢使用BEM,他们认为:
BEM并不能完美地解决所有的问题,但是其**可以借鉴:
如果认为其命名冗长不可取,那么完全可以取其精华、去其“糟粕”。
本文以考拉社区后台工程(kaola-communityms-web)为例进行分析。
首先介绍一个可视化打包分析工具——webpack-bundle-analyzer。
kaola-communityms-web已经做了如下配置:
// webapp/config/index.js
module.exports = {
build: {
//...
bundleAnalyzerReport: process.env.npm_config_report
},
}
// webapp/build/webpack.prod.conf.js
if (config.build.bundleAnalyzerReport) {
var BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin
webpackConfig.plugins.push(new BundleAnalyzerPlugin())
}
所以添加指令:
// package.json
{
// ...
"scripts":{
// ...
"analyz": "NODE_ENV=production npm_config_report=true npm run build"
}
}
执行指令npm run analyz即可启动webpack-bundle-analyzer。
其他工具如 webpack analyse、webpack chart等不再做详细介绍。
webpack打包可以总结为:
所以对于kaola-communityms-web(vue-cli构建,单入口),在默认情况下,执行npm run build会把所有js代码打包成3个文件
其中app.[hash].js文件在页面很多时会很大、加载缓慢(特别是在加载一些只在特定环境下才会使用到的阻塞的代码的时候),所以需要把大的文件拆分成多个小块。另外并不是每个页面都需要所有的资源,如果能只加载当前页面所需资源,那页面加载速度将得到有效提升。
对kaola-communityms-web进行本地打包,打包情况如下所示:
可以看到vue-highcharts.js过大,考虑到只有一个页面用到了vue-highcharts,可以把它单独打个包;element-ui中的方法并不是所有页面都有用到,可以考虑按需加载,或单独打包;在static/js/vendor.[hash].js和static/js/app.[hash].js中均打包了element-ui,需要移除重复打包;一些没有用到的库可以移除掉。
所以可以优化点的有:
Vue懒加载——路由懒加载
把不同路由对应的组件分割成不同的代码块,然后当路由被访问时才加载对应组件。结合Vue的异步组件和Webpack的代码分割功能(Code splitting),可以轻松实现路由组件的懒加载;另外,在Webpack 2中,我们可以使用动态import语法来定义代码分块点。结合以上两点,定义一个能够被Webpack自动代码分割的异步组件即:
const Foo = () => import('./Foo.vue')
在路由配置中:
const router = new VueRouter({
routes: [
{ path: '/foo', component: Foo }
]
})
如果想把某个路由下的所有组件都打包在同个异步块(chunk)中,只需要使用命名chunk(一个特殊的注释语法)来提供chunk name:
const Foo = () => import(/* webpackChunkName: "group-foo" */ './Foo.vue')
const Bar = () => import(/* webpackChunkName: "group-foo" */ './Bar.vue')
const Baz = () => import(/* webpackChunkName: "group-foo" */ './Baz.vue')
Webpack会将任何一个异步模块与相同的块名称组合到相同的异步块中,即上述三个组件Foo、Bar、Baz将被打包到同一个chunk中。
Vue懒加载——组件懒加载:只下载当前页面需要执行的代码、下载之后缓存起来以供再次渲染,这里用到了vue的异步组件。
new Vue({
// ...
components: {
'AsyncCmp': () => import('./AsyncCmp')
}
})
注:按需加载(一个模块打包一个文件),需要配置webpack的output:
output: {
path: config.build.assetsRoot,
filename: utils.assetsPath('js/[name].[chunkhash].js'),
chunkFilename: utils.assetsPath('js/[id].[chunkhash].js') //每个模块都会在打包目录下生成相应的js/[id].[chunkhash].js文件
}
这里有两个问题需要额外提下:
以外源性脚本引入某些不需要改动的模块(webpack的externals):webpack externals配置选项提供了从输出的bundle中排除依赖的方法,它可以防止把某些import的包打包到bundle中,在运行时(runtime)才去从外部获取这些扩展依赖,比如从CND引入jQuery,而不是把它打包:
//index.html
<script
src="https://code.jquery.com/jquery-3.1.0.js"
integrity="sha256-slogkvB1K3VOkzAI8QITxV3VzpOnkeNVsKvtkYLMjfk="
crossorigin="anonymous">
</script>
//webpack.config.js
externals: {
jquery: 'jQuery'
}
// my-component.vue
import $ from 'jquery';
$('.my-element').animate(...);//可以正常运行
又比如项目开发中常用到的 moment等比较大的模块,如果必须引入的话,可以考虑外部引入,再借助 externals 予以指定, webpack可以处理使之不参与打包,而依旧可以在代码中通过CMD、AMD或者window/global全局的方式访问。
webpack插件:webpack提供了一个插件 DllPlugin ,用于将不常变动的js单独打包。DllPlugin 和 DllReferencePlugin 提供了以大幅度提高构建时间性能的方式拆分软件包的方法。其中原理是,将特定的第三方NPM包模块提前构建,然后通过页面引入。这不仅能够使得 vendor 文件大幅度减小,同时,也极大地提高了构建速度。对于kaola-communityms-web,先创建webpack.dll.conf.js、配置需要单独打包的模块,在webpack.prod.conf.js中添加DllReferencePlugin插件配置,在webpack.base.conf.js中添加externals,删掉代码中对这些模块的多余的引用,执行指令即可。
// webpack.dll.conf.js
// ...
module.exports = {
// 你想要打包的模块的数组
entry: {
vuecharts:['vue2-highcharts'],
vendor: ['vue', 'lodash', 'vuex', 'axios', 'vue-router', 'element-ui','moment']
},
plugins: [
new webpack.DllPlugin({
path: path.join(__dirname, '.', '[name]-manifest.json'),
name: '[name]_library',
context: __dirname
})
// ...
]
// ...
}
// webpack.prod.conf.js
// ...
plugins: [
new webpack.DllReferencePlugin({
context: __dirname,
manifest: merge(require('./vuecharts-manifest.json'),require('./vendor-manifest.json'))
})
// ...
]
// webpack.base.conf.js
// ...
externals: {
'vue': 'Vue',
'vue-router': 'VueRouter',
'elemenct-ui': 'ELEMENT',
'lodash':'lodash',
'vuex':'vuex',
'axios':'axios',
'vue-highcharts':'vue2-highcharts',
'moment':'moment'
}
// 添加指令
// package.json
"dll": "webpack --config ./build/webpack.dll.conf.js"
执行npm run dll后生成两个manifest配置文件(vendor-manifest.json、vuecharts-manifest.json)和两个打包文件:
鉴于篇幅,具体用法可见:webpack.dll.conf.js、externals&Dll Reference。
happypack可以加速代码构建。
webpack提供的UglifyJS插件由于采用单线程压缩,速度很慢,webpack-parallel-uglify-plugin插件可以并行运行UglifyJS插件,可以有效减少构建时间(UglifyJsPlugin 不仅可以将未使用的 exports 清除,还能去掉很多不必要的代码,如无用的条件代码、未使用的变量、不可达代码等)。
移除组件中没有用到的引入;
不生成.map文件
// config/index.js
module.exports = {
build: {
// ...
productionSourceMap: false
}
另外:webpack3新功能Scope Hoisting(作用域提升),只需在配置文件中添加一个新的插件,就可以让 Webpack 打包出来的代码文件更小、运行的更快。参见 Webpack 3 的新功能:Scope Hoisting。
优化后的打包情况:
优化后的首页资源加载情况:
可以看到优化后打包时间从29418ms减少到了11998ms,打包资源大小从1.53MB减少到了367.87KB,并且实现了按需加载(没有加载所有资源)。
性能优化范围广、方法多,还有很多可以提升打包速度、打包文件大小、首屏加载等性能问题的方法,本文只是对部分方法进行学习总结,还需要不断学习、研究更多方案。
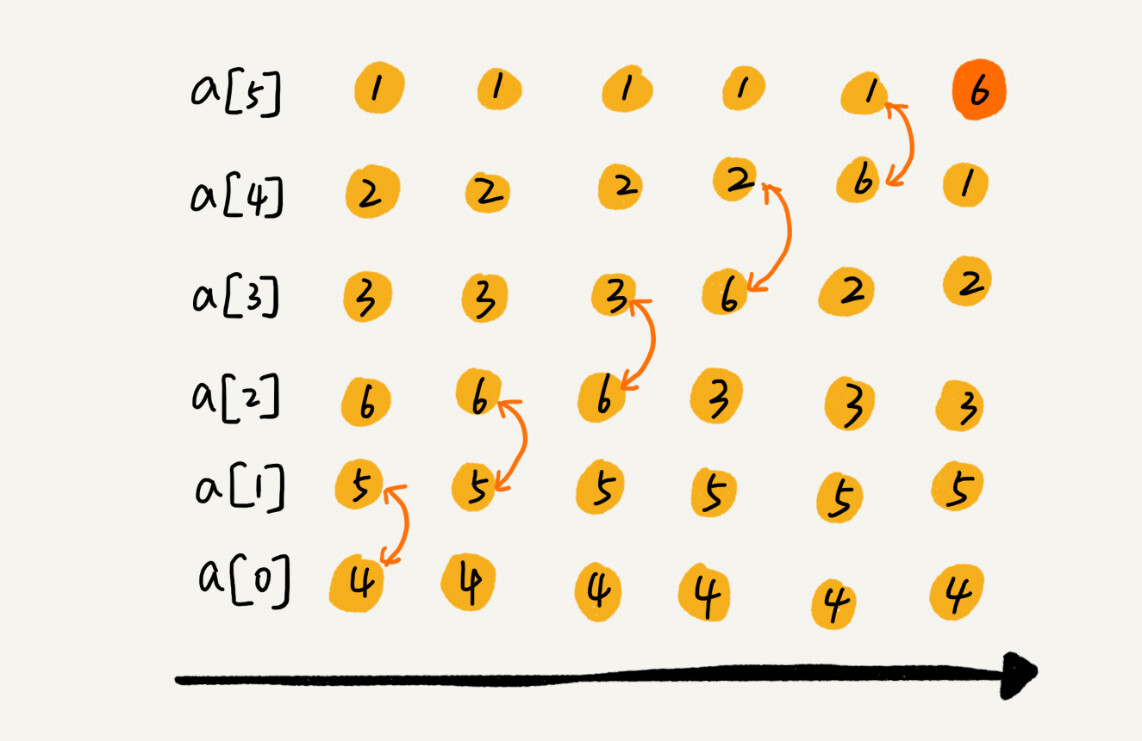
2018年11月29日
百度百科
程序中的所有数在计算机内存中都是以二进制的形式存储的。位运算就是直接对整数在内存中的二进制位进行操作。
Wiki
现代编程语言允许编程者直接使用抽象方法而不是位运算进行运算。进行位运算的源代码可以使用的按位运算有:AND,OR,XOR,NOT和位移。
位运算的核心是按位运算符:& (and,按位与),| (or,按位或),~ (not,按位取反),^ (xor,按位异或),<< (左移),>> (右移)。
and运算(&)通常用于二进制的取位操作,如 A & 1 就是取A的二进制的最末位。这可以用来判断一个整数的奇偶,二进制的最末位为0表示该数为偶数、最末位为1表示该数为奇数;
or运算(|)通常用于二进制特定位上的无条件赋值,如 A | 1 就是把A的二进制的最末位强行变成1。如果需要把A最末位变成0,只需: A or 1 - 1,其实际意义就是把A强行变成最接近的偶数;
not运算(~)用来取反,使用时要注意整数类型有没有符号。如果not的对象是无符号整数,那么得到的值就是它与该类型上界的差;如果not的对象是有符号的整数,最高位的变化将导致正负颠倒,并且数的绝对值会与原值差1,即 -a = not a + 1,这种整数存储方式叫做“补码”(正数的补码和原码相同,负数的补码是该数的绝对值的二进制形式按位取反后再加1);
xor运算(^),2个二进制数相应位不同则为1、相同则为0。xor运算的逆运算是它本身,也就是说两次异或同一个数、结果不变,即 (A xor B) xor B = A。所以可以用xor运算来进行简单加密,B就是密钥:小明想对小红说5201314,不想让别人看到,所以小明和小红约定拿小红的生日19990101作为密钥 ,加密得到 5201314 xor 19990101 = 25058295;小明把25058295发给小红,小红拿19990101解密,得到 25058295 xor 19990101 = 5201314;
延伸:利用两个互为逆运算且其中一个满足交换律的运算符对两个数进行交换
x = x # y
y = x @ y // 执行第一句后x变为 x # y,所以第二句即 y = x # y @ y,因为#和@互为逆运算,所以这里y=x、y变成了原来的x
x = x @ y // 第三句实际被赋值为 x = (x # y) @ x,如果#满足交换律,那么 x = y # x @ x = y,即x变成了原来的y。至此,x和y的值交换了。
利用上述算法,我们可以知道,加法和减法互为逆运算、且加法满足交换律,把#换成+、@换成-,那么就可以利用+、-写一个不需要临时变量的swap过程(JavaScript):
function swap (a, b) {
a = a + b
b = a - b
a = a - b
return {a, b}
}
var a=1, b=2
swap(a, b) // {a:2, b:1}同样的,xor的逆运算是它本身,且xor满足交换律,所以可以用xor实现swap(JavaScript):
function swap (a, b) {
a = a ^ b
b = a ^ b
a = a ^ b
return {a, b}
}
var a=1, b=2
swap(a, b) // {a:2, b:1}<<运算(左移),a << b 表示把a转为二进制后左移b位(在后面添加b个0),这样操作实际上就是把a乘以2的b次方。通常认为 a << 1 比 a * 2更快,因为前者是更底层的一些操作。
定义一些常量可能会用到<<运算:你可以很方便地用 1 << 16 - 1 来表示65535(16位能表示的最大整数);
>>运算(右移),a >> b 表示把a转为二进制后右移b位(去掉末b位),相当于a除以2的b次方(取整)。用右移来代替除法运算可以使程序效率大大提高。
C语言中运算符之间的优先顺序(从高到底排序):
| 1 | ~ |
|---|---|
| 2 | <<、>> |
| 3 | & |
| 4 | ^ |
| 5 | | |
| 6 | &=、^=、|=、<<=、>>= |
技巧:
取反:~A 或 ALL_BITS ^ A;【ALL_BITS = (1<<n) - 1,其中n指数据以n位存储,比如数据以4位存储,则n为4,ALL_BITS为1111】
右起第一个1置0:A & (A -1);
去掉最后一位:A >> 1;
在最后追加一位0:A << 1;
在最后追加一位1:A << 1 + 1;
把最后一位变成1:A | 1;
把最后一位变成0:A | 1 - 1;
最后一位取反:A xor 1;
把右数第k位变成1:A | (1 << (k - 1));
右数第k位是否是1:A & (1 << (k - 1)) != 0;
把右数第k位变成0:A & ~(1 << (k - 1));// 因为0取反后是1,即实际上与A按位和的是01…1(k-1位1)
右数第k位取反:A ^ (1 << (k - 1));
取末一位:A & 1;
取末三位:A & 7; // 原理:利用 任何数 & 1 = 任何数
取末k位:A & (Math.pow(2, k) - 1);// 原理:二进制数 1…1(k个1)的十进制值是
$$
2^k - 1
$$
取右数第k位:A >> (k - 1) & 1;
把末k位变成1:A | (1 << (k - 1));
末k位取反:A ^ (1 << (k - 1));
把最右边连续的1变成0:A & (A + 1);// 原理,1 + 1 = 0向前进位、0 + 1 = 1不进位
把右数第一个0变成1:A | (A + 1);// 原理同上,进位后第一位0变成了1,其后的连续1变成了0
把最右边连续的0变成1:A | (A - 1);
取最右边连续的1:(A ^ (A + 1) ) >> 1;
去掉右起第一个1的左边(取最后一个1的位置):A & -A;// 原理:负数用其正值的补码形式表示;一个数补码是该数的反码+1
获取所有1位: ~0;【如果考虑常数0可以是任何数字类型,那么可以用 ~(A & 0),来让编辑器根据A给出一个上下文、从而能给定位的长度】
0 ^ A = A;A ^ A = 0;A ^ B ^ B = A(^满足交换律)。
举例说明:
// 例1.计算给定数字的二进制表示中的1的数量
// 分析:利用 A & (A-1)循环移除(置0)最后一个1,累计消去的1的个数
function count_one (n) {
let count = 0
while (n) {
n = n & (n-1)
count++
}
return count
}// 例2.计算对一个范围[m,n]内所有二进制数做和操作后的结果(包括m、n),其中0<=m<=n<=2147483647。例如[5,7],这个范围内的数有5、6、7,二进制做和操作:101 & 110 & 111 = 100,结果就是4。
// 分析:m和n左边相同的位相与之后的结果不会变,相同的位的右边必然为0(因为这个范围的相同位右边每一位都有出现0的可能),所以找出m和n左边相同的部分、右边置0即是结果。
function rangeBitwiseAnd (m, n) {
let count = 0
if (m!=n) {
m>>=1
n>>=1
count++
}
return m<<count
}
// 其他方法参考:http://www.cnblogs.com/grandyang/p/4431646.html// 例3.计算一个32位整数的二进制中1的个数的奇偶性,当输入数据的二进制表示里有偶数个1时输出0,有奇数个1时则输出1。
function even_ones (n) {
n = n ^ (n >> 1)
n = n ^ (n >> 2)
n = n ^ (n >> 4)
n = n ^ (n >> 8)
n = n ^ (n >> 18)
return n & 1
}例3分析(分治的**):
// 例4.计算一个32位整数的二进制中1的个数(用不同于例1的方法)
// 利用与例3相同的分治**,先计算相邻2位有几个1,再计算相邻4位、8位、16位......有几个1。
// 如何计算相邻2位有几个1? => A & 1 计算结果的最后2位表示A的末位有几个1,(A >> 1) & 1 计算结果的最后2位表示A的右数第二位有几个1,那么 (A & 1) + ((A >> 1) & 1) 计算结果的最后2位就可以表示A的右数2位有几个1 => 如此,A = (A & 0x55555555) + ((A >> 1) & 0x55555555) 就可以得到从右数每2位中有几个1;
// 计算相邻4位有几个1? => 计算相邻4位需要把上一步的结果两位两位相加 => A & 3 可以得到末2位的值,即末1、2位中1的个数;(A >> 2) & 3 可以得到右数第3、4位的值,即末3、4位中1的个数 => A = (A & 0x33333333) + ((A >> 2) & 0x33333333) 将相邻4位(如末1、2、3、4位)中存储的1的个数的值相加,就可以得到从右数每相邻4位中有几个1;
// 计算算相邻8位有几个1? => 即将上一步的结果4个4个相加 => A = (A & 0x0F0F0F0F) + ((A >> 4) & 0x0F0F0F0F) 即可得到每相邻8位中有几个1;
// 计算相邻16位有几个1? => A = (A & 0x00FF00FF) + ((A >> 8) & 0x00FF00FF);
// 计算相邻32位有几个1? => A = (A & 0x0000FFFF) + ((A >> 16) & 0x0000FFFF);
// 最后得到的A即是这个整数中1的个数。
// 具体实现略。// 例5.输出一个32位无符号整数的二进制表示倒序后的数
// 注:当然也可以用非位操作方法,如:https://leetcode.com/problems/reverse-bits/description/
// 方法1:
// 分析:利用与例3、4相同的分治**,先把从右起相邻的2位两两交换(即交换1、2位,3、4位,...,2n+1、2n+2位),再以2位为长度相邻4位进行交换,...,最后以16位为长度交换二进制位记得到最后结果(当然先以16位为长度交换、再以8位交换...、以2位交换、相邻2位交换也可以)
function reverseBinary (n) {
n = ((n & 0x55555555) << 1) | ((n & 0xAAAAAAAA) >> 1)
n = ((n & 0x33333333) << 2) | ((n & 0xCCCCCCCC) >> 2)
n = ((n & 0x0F0F0F0F) << 4) | ((n & 0xF0F0F0F0) >> 4)
n = ((n & 0x00FF00FF) << 8) | ((n & 0xFF00FF00) >> 8)
n = ((n & 0x0000FFFF) << 16) | ((n & 0xFFFF0000) >> 16) // 或 n = (n << 16) | (n >>16);
return n
}
// 方法2:
// 分析:从二进制表达式一端(低位或高位都可)开始遍历,取出的数存储在result中,把result左移一位,如此原来的最后一位就被移到了前一位,重复遍历32位,即可把二进制表达式反转
function reverseBinary (n) {
let result = 0
let mask = 1
for (let i=0;i<32;i++) {
result<<=1
if (mask & n) {
result |= 1
}
mask<<=1
}
return result
}// 例6.给定一个32位整数N,找出一个2的最大幂值n,其值小于等于N。例如N=3,则n为1。
// 分析:即把N的二进制表达式的最左边的1的位置找出来 => 把N的左起第一个1后的所有位都变为1,然后+1再右移1位,即为结果
function largest_power (n) {
n = n | (n>>1)
n = n | (n>>2)
n = n | (n>>4)
n = n | (n>>8)
n = n | (n>>16)
return (n+1)>>1
}// 例7.用O(1)的时间检测整数n是否是2的幂次
// 分析:一个数是2的幂次需满足两个条件:1)>0;2)其二进制表示中只有一位1; => 因为只有一位1,所以用 A & (A-1)消去最后一个1(也是唯一一个1)后结果应该是0
function isPowerOfTwo (n) {
return !(n & (n-1))
}// 例8.如果要将整数A转换为B,需要改变多少个bit位?
// 分析:将A转换为B,需要改变A中与B不同的bit位,所以问题转换为A与B中有多少位不同;那么只需 A xor B 后计算1的个数
function changeBitNum (A, B) {
let diff = A ^ B
let count = 0
while (diff) {
diff = diff & (diff-1)
count++
}
return count
}// 例9.是否是4的倍数
// 分析:一个数是4的倍数,4是2的2次方,所以这个数是2的偶数次幂(0,2,4,...)。所以其需满足:1)>0;2)是2的偶数次幂,即二进制表式的1在偶数bit位上;3)其二进制表示中只有一位为1。
function isPowerOfFour (n) {
return !!(n & 0x55555555) && !(n & (n-1)) // 0x55555555是十六进制,其2进制是1010101010101010101010101010101,所以 n & 0x55555555用来判断n的二进制表达式的1是否在偶数bit位上
}// 例10.两个整数相加
// 分析:我们知道在加法运算中,每一数位上的数等于基数时需要向前一位数进一。所以两数相加可以转换为对两数的“不考虑进位的和”和“只考虑进位的产生值”求和,当不再产生进位时就可以得到最终结果
function getSum (a, b) {
return b==0 ? a : getSum(a^b, (a&b)<<1) // 只有1^0或0^1时、a^b会得到1、其他情况(0^0、不需要进位、值就是0,1^1、需要进位、本位值为0)都是0,所以a^b得到的就是“不考虑进位的和”;(a&b)<<1就是本轮进位的结果。当不再产生进位时,最终的和就是a。
}// 例11.给定0,1,2,...,n的n个不同的数字,找出其中缺失的数字(假设有且仅有一个数字缺失),比如nums = [0, 1, 3],则缺失的是2。(当然可以用位运算之外的其他方法)
// 分析:1)a = 0 ^ a,即0和任何数字异或、结果还是这个数字;2)0 = a ^ a,即一个整数与自己异或、结果为0 => 所以将下标和值集合中相同的数字两两消除、最后和数组长度(用来消除最后一个数,它没有相应的i可以与其两两消除)异或、即得到多出来的数字
function missingNumber(nums) {
var ret = 0;
for(let i = 0; i < nums.length; ++i) {
ret ^= i;
ret ^= nums[i];
}
return ret^=nums.length;
}// 例12.数组中,只有一个数出现一次,其他都出现两次,找出出现一次的数
// 分析:将所有数进行异或运算,出现两次的数可以用异或运算两两消除,剩下的就是唯一的出现一次的数
function onceNumber (nums) {
let result = 0
nums.map(item => {
result ^= item
})
return result
}// 例13.数组中,只有一个数出现一次,其他都出现三次,找出出现一次的数
// 方法1:
// 分析:例12是把相同的数两两消除、剩下的几位结果,那么这题要如何消除相同的数呢? => 比如数组A=[1,2,2,2];把每一项都转换为二进制,则A=[01,10,10,10];按位统计数组中的数据中1的个数,则右数第一位:1,右数第三位:3;把这两个数模3,则右数第一位模3:1,右数第三位模3:0,这两个数即表示数组A中按位统计右数第一位只有一个数有1、右数第二位有3个数有1;这样就把出现3次的数的某一位消除了。将上面的结果移位组合,(0<<1) | 1 = 01,即十进制的1,所以只出现一次的那个数是1。
// 假定是32位存储
function onceNumber2 (nums) {
let len = nums.length
let bitArr = [...new Array(32)].map(item => {
return 0
})
let result = 0
for (let i=0; i<32; i++) {
for (let j=0; j<len; j++){
// 按位统计数组中每个数1出现的次数
bitArr[i] += (nums[j]>>i) & 1
}
result |= (bitArr[i] % 3)<<i
}
return result
}
// 方法2:
// 分析:利用技巧 0 ^ A = A;A ^ A = 0。假定一个结果集R初始值为0,利用 0 ^ A = A 可以在R中没有A时把A加入R中,利用 A ^ A = 0 可以在R中已有A时把A清除掉。 => 这个时候有一个问题,出现3次的数因为前2个已被清除、所以第3个数又可以存入R中,那么就需要把出现2次的数放到另一个集合Z中,在判断是否存入R时、除了判断R中有没有、还要判断Z中有没有 => 用ones存储出现1次的数,用twos存储出现2次的数 => 1)存入ones的条件:ones没有切twos中没有(排除第3次出现);2)存入twos的条件:twos中没有且ones中没有(ones中已被消除掉)。 => 所以整个的过程是:
// 1)当一个数出现1次时,存入ones;
// 2)当这个数出现2次时,与ones中的该数异或消除,并存入two中;
// 3)当这个数出现3次时,因为two中有该数,所以不能存入ones,并与tows中的该数异或消除。
function onceNumber2 (nums) {
let ones = 0, twos = 0
let len = nums.length
for (let i=0; i<len; i++) {
ones = (ones ^ nums[i]) & ~twos
twos = (twos ^ nums[i]) & ~ones
}
return ones
}// 例14.数组中,只有两个数出现一次,其他都出现两次,找出出现一次的两个数
// 分析:受例12启发,出现两次的数可以通过异或操作两两消除,那么出现一次的两个数该如何区分呢?如果把数组分为2个数组,每个数组都只有一个只出现一次的数、其他数都出现两次,那么就可以用例12的方法分别找出2个数组中只出现一次的数了。 => 不妨假设只出现一次的这两个数是a、b,对数组中所有数进行异或操作,结果是result = a ^ b,因为a != b,所以result != 0 => 即result的二进制表示中至少有一位是1。 => 某位的异或结果为1,表示a、b的二进制表达式中该位一个为0一个为1,那么我们就可以通过判断该位是否是1来把数组分成2个数组(这样a、b肯定在两个不同的数组中,且出现两次的数、因为其每一位都相同、所以被分到同一个数组中)
function onceTwoNumber (nums) {
let len = nums.length
let diff = 0
// 对数组中所有数都进行异或操作
for (let i=0; i<len; i++) {
diff ^= nums[i]
}
// 利用技巧 A & -A 去掉右起第一个1的左边(取最后一个1的位置)
diff &= -diff
let result = [0, 0]
for (let i=0; i<len; i++) {
let cur = nums[i]
if (cur&diff) {
result[0] ^= cur
} else {
result[1] ^= cur
}
}
return result
}// 例15.使用二进制进行子集枚举。给定一个含不同整数的集合,枚举其所有子集。
// 分析:
// 1. 一个有n个元素的集合,它共用2^n个子集(包括空集和全集)(因为这n个元素、每个元素都有取/不取两种可能);
// 2. 一个n位二进制数,它可以表示0~2^n-1范围的2^n个整数,所以可以用一个n位二进制数来表示该集合某个下标的数取/不取。
var subsets = function(nums) {
let n = nums.length
let subsetsNum = Math.pow(2, n)
let result = [...new Array(subsetsNum)].map(item => {
return []
})
for (let i=0; i<n; i++) {
for (let j=0; j<subsetsNum; j++) {
if ((j>>i) & 1) {
result[j].push(nums[i])
}
}
}
return result
};在2D环境下,常见的碰撞检测的方法有:
1.外接图形判别法
2.光线投射法
3.分离轴定理
4.其他
概念:判断任意两个(无旋转)矩形的任意一边是否无间距,从而判断是否碰撞。
两矩形碰撞的各种情况:
得出两矩形碰撞条件:
rect1.x < rect2.x + rect2.width &&
rect1.x + rect1.width > rect2.x &&
rect1.y < rect2.y + rect2.height &&
rect1.y + rect1.height > rect2.y
示例:
适用案例:
缺点:
概念:通过判断任意两个圆形的圆心距离是否小于两圆半径之和,小于则为碰撞。
两圆碰撞条件:
Math.sqrt(Math.pow(circleA.x - circleB.x, 2) +
Math.pow(circleA.y - circleB.y, 2))
< circleA.radius + circleB.radius
示例:
适用案例:
缺点:
概念:通过找出矩形上离圆心最近的点,然后通过判断该点与圆心的距离是否小于圆的半径,若小于则为碰撞。
那如何找出矩形上离圆心最近的点呢?我们从x轴、y轴两个方向分别进行寻找。为了方便描述,我们先约定以下变量:
首先是x轴:
如果圆心在矩形的左侧(if(circle.x < rect.x)),那么closestPoint.x = rect.x。
如果圆心在矩形右侧,closestPoint.x = rect.x + rect.w。
如果圆心在矩形的正上下方,closestPoint.x = circle.x。
同理,对于y轴:
如果圆心在矩形的上方(if(circle.y < rect.y)),那么closestPoint.y = rect.y;
如果圆心在矩形的下方,closestPoint.y = rect.y + rect.h;
如果圆心在矩形的正左右两侧,closestPoint.y = circle.y。
因此,通过上述方法即可找出矩形上离圆心最近的点了,然后通过【两点之间的距离公式】得出最近点与圆心的距离,最后将其与圆的半径比较,如果比圆的半径小,则发生碰撞。
示例:
https://codepen.io/JChehe/pen/aWqpdo
缺点:
概念:即使矩形以其中心为旋转轴进行了旋转,但是判断它与圆形是否发生碰撞的本质还是找出矩形上离圆心的最近点。
对于旋转后的矩形,要找出其离圆心最近的点似乎有些困难。其实我们可以将矩形的旋转看作是整个画布的旋转。那么我们将画布(Canvas)反向旋转“矩形旋转的角度”后,所看到的就是上一个方法【圆形与矩形(无旋转)】的情形。因此,我们只需要求出画布旋转后的圆心位置,即可使用【圆形与矩形(无旋转)】的判断方法了。
旋转后的圆心坐标公式:
该公式的推导过程:
根据下图,计算某个点绕另外一个点旋转一定角度后的坐标。我们设A(x,y)绕B(a,b)旋转β度之后的位置为C(c,d)。
得到旋转后的圆心坐标值后,即可使用【圆形与矩形(无旋转)】方法进行碰撞检测了。
案例:
https://codepen.io/JChehe/pen/dWmYjO
优点:
概念:将地图(场景)划分为一个个格子。地图中参与检测的对象都存储着自身所在格子的坐标,那么可以认为两个物体在相邻格子时为碰撞(或者两个物体在同一格才为碰撞)。
另外,采用此方式的前提是,地图中所有可能参与碰撞的物体都要是格子单元的大小或者是其整数倍。
蓝色的X为障碍物:
| X | X | X | ||||||
|---|---|---|---|---|---|---|---|---|
| X | X | X | ||||||
| X | X | |||||||
| X | X | |||||||
| X | X | X | X | X | X |
实现方法:
// 通过特定标识指定(非)可行区域
map = [
[0,0,1,1,1,0,0,0,0],
[0,1,1,0,0,1,0,0,0],
[0,1,0,0,0,0,1,0,0],
[0,1,0,0,0,0,1,0,0],
[0,1,1,1,1,1,1,0,0]
],
// 设定角色的初始位置
player = {left:2,top:2}
//移动前(后)判断角色的下一步的动作(如不能前行等)
...
示例:
适用案例:
缺点:
概念:以像素级别检测物体之间是否存在重叠,从而判断是否碰撞。
实现方法有多种,下面列举在Canvas中的两种实现方式:
注意:当待检测的碰撞物体为两个时,第一种方法需要两个offscreen canvas,而第二种只需要一个。
offscreen canvas:与之相关的是 offscreen rendering。正如其名,它会在某个地方进行渲染,但不是屏幕。“某个地方”其实是内存。渲染到内存比渲染到屏幕更快。—— Offscreen Rendering
当然,我们这里并不是利用offscreen render的性能优势,而是利用offscreen canvas保存独立物体像素。换句话说,onscreen canvas只是起展示作用,碰撞检测实在offscreen canvas中进行。
另外,由于需要逐像素检测,若对整个Canvas内所有像素都进行此操作,无疑会浪费很多资源,因此我们可以先通过运算得到两者相交区域,然后只对该区域内的像素进行检测即可。
图例:
示例——第一种实现方式:
适用案例:
缺点:
光线投射法
概念:通过检测两个物体的速度矢量是否存在交点,且该交点满足一定条件。
以下图抛球入桶为例,画一条与物体(球)的速度向量相重合的线(#1),然后再从另一个待检测物体(桶)出发,连线到前一个物体,绘制第二条线(#2),根据两条线的交点位置来判定是否发生了碰撞。
抛球入桶图例:
在小球飞行的过程中,需要不断计算两直线的交点。
当满足以下两个条件时,那么就可以认为小球落入桶中(发生碰撞):
示例:
适用案例:
优点:
缺点:
概念:通过判断任意两个凸多边形在任意角度下的投影是否均存在重叠,来判断是否发生碰撞。若在某一角度光源下,两物体的投影存在间隙,则为不碰撞,否则为发生碰撞。
图例:
遍历所有的角度是不现实的,那如何确定投影轴呢?其实投影轴的数量与多边形的边数相等即可。
polygon /'pa:liga:n/ n.多边形
axis /'æksis/ n.轴,中枢 ; 复数axes /'æksi:z/
projection n.投影
project n.工程,项目;v.计划,投射,放映
overlap vt.重叠
以较高抽象层次判断两个凸多边形是否碰撞:
上述代码有几个需要解决的地方:
投影轴
如下图所示,我们使用一条从p1指向p2的向量来表示多边形的某条边,我们称之为边缘向量。在分离轴定理中,还需要确定一条垂直于边缘向量的法向量,我们称之为边缘法向量。
投影轴平行于边缘法向量。投影轴的位置不限,因为其长度是无限的,故而多边形在该轴上的投影是一样的。该轴的方向才是关键的。
// 以原点(0,0)为始,顶点为末。最后通过向量减法得到边缘向量。
var v1 = new Vector(p1.x, p1.y)
v2 = new Vector(p2.x, p2.y)
// 首先得到边缘向量,然后再通过边缘向量获得相应边缘法向量(单位向量)。
// 两向量相减得到边缘向量 p2p1(注:上面应该有个右箭头,以表示向量)。
// 设向量 p2p1 为(A,B),那么其法向量通过 x1x2+y1y2 = 0 (假设法向量通过原点(0,0))可得:(-B,A) 或(=(B,-A)。
axis = v1.edge(v2).normal()
以下是向量对象的部分实现
var Vector = function(x, y) {
this.x = x
this.y = y
}
Vector.prototype = {
// 获取向量大小(即向量的模),即两点间距离
getMagnitude: function() {
return Math.sqrt(Math.pow(this.x, 2),
Math.pow(this.y, 2))
},
// 点积的几何意义之一是:一个向量在平行于另一个向量方向上的投影的数值乘积。
// 后续将会用其计算出投影的长度
dotProduct: function(vector) {
return this.x * vector.x + this.y + vector.y
},
// 向量相减 得到边
subtarct: function(vector) {
var v = new Vector()
v.x = this.x - vector.x
v.y = this.y - vector.y
return v
},
edge: function(vector) {
return this.substract(vector)
},
// 获取当前向量的法向量(垂直)
perpendicular: function() {
var v = new Vector()
v.x = this.y
v.y = 0 - this.x
return v
},
// 获取单位向量(即向量大小为1,用于表示向量方向),一个非零向量除以它的模即可得到单位向量
normalize: function() {
var v = new Vector(0, 0)
m = this.getMagnitude()
if(m !== 0) {
v.x = this.x / m
v.y = this.y /m
}
return v
},
// 获取边缘法向量的单位向量,即投影轴
normal: function() {
var p = this.perpendicular()
return p .normalize()
}
}

投影
投影的大小:通过将一个多边形上的每个顶点与原点(0,0)组成的向量,投影到某一投影轴上,然后保留该多边形在该投影轴上所有投影中的最大值和最小值,这样即可表示一个多边形在某投影轴上的投影了。
判断两多边形的投影是否重合:
projection1.max > projection2.min && projection2.max > projection1.min
为了易于理解,示例图将坐标轴原点(0,0)放置于三角形边1投影轴的适当位置。
由上述可得投影对象:
// 用最大和最小值表示某一凸多边形在某一投影轴上的投影位置
var Projection = function (min, max) {
this.min
this.max
}
projection.prototype = {
// 判断两投影是否重叠
overlaps: function(projection) {
return this.max > projection.min && projection.max > this.min
}
}
如何得到向量在投影轴上的长度?
向量的点积的其中一个几何含义是:一个向量在平行于另一个向量方向上的投影的数值乘积。
投影的长度即为 |A|cos0 = 
// 根据多边形的每个定点,得到投影的最大和最小值,以表示投影。
function project = function (axis) {
var scalars = [], v = new Vector()
this.points.forEach(function (point) {
v.x = point.x
v.y = point.y
scalars.push(v.dotProduct(axis))
})
return new Projection(Math.min.apply(Math, scalars),
Math.max,apply(Math, scalars))
}
圆形与多边形之间的碰撞检测
由于圆形可近似地看成一个有无数条边的正多边形,而我们不可能按照这些边一一进行投影与测试。我们只需将圆形投射到一条投影轴即可,这条投影轴就是圆心与多边形定点中最近的一点的连线,如图所示:
因此,该投影轴和多边形自身的投影轴就组成了一组待检测的投影轴了。
而对于圆形与圆形之间的碰撞检测我们在【外接图形判别法——圆形碰撞】中已经介绍过了。
示例:
适用案例:
优点:
缺点:
通常来说,如果碰撞之后,相撞的双方依然存在,那么就需要将两者分开。分开之后,可以使原来相撞的两物体彼此弹开,也可以让他们黏在一起,还可以根据具体需要来实现其他行为。如果要将两者分来,需要用到最小平移量(Minimum Translation Vector,MIT)。
若每个周期都需要对全部物体进行两两判断,会造成浪费(比如有些物体分布在不同区域,根本不会发生碰撞)。所以,可以将碰撞分为两个阶段:粗略和精细。
粗略阶段
粗略阶段能为你提供有可能碰撞的实体列表。这可通过一些特殊的数据结构实现,它们能为你提供信息:实体存在哪里和哪些实体在其周围。这些数据结构可以使:四叉树、R树或空间哈希映射等。
精细阶段
当你有了较小的实体列表,你可以利用精细阶段的算法(如上述讲述的碰撞算法)得到一个确切的答案。
原文:
https://aotu.io/notes/2017/02/16/2d-collision-detection/index.html
JavaScript this指向总结
this是在运行时绑定的、而不是在定义时绑定,它的上下文取决于函数调用时的各种条件。this的绑定和函数声明的位置没有任何关系,只取决于函数的调用方式。
当一个函数被调用时,会创建一个活动记录(也称执行上下文)。这个记录会包含函数在哪里被调用(调用栈)、函数的调用方法、传入的参数等信息。this就是记录的其中一个属性,会在函数执行的过程中用到。
判断this的指向,我们需要先找到函数的调用位置,然后判断应用下面四条规则中的哪一条:
function foo () {
console.log(this.a);
}
var a = 2;
foo(); // 2
foo()是直接使用不带任何修饰的函数引用进行调用的,因此只能使用默认绑定规则、this指向全局对象。
注意:如果foo在严格模式下,默认绑定将绑定到undefined、而不是全局对象。(只要foo不在严格模式下,此处this就可以利用默认规则绑定到全局对象;只有foo是严格模式时、此处this绑定到undefined)
function foo () {
console.log(this.a);
}
var obj = {
a: 2,
foo: foo
};
obj.foo(); // 2
调用位置会使用obj上下文来引用函数,因此可以说函数被调用时obj对象“拥有”或者“包含”foo函数(实际上foo不属于obj对象,它只是被当做引用属性添加到obj中)。
当函数引用有上下文对象时,隐式绑定规则会把函数调用中的this绑定到这个上下文对象。因为调用foo()时this被绑定到obj,因此this.a和obj.a是一样的。
对象属性引用链中,只有最后一个调用者(直接调用者)会影响调用位置:
function foo () {
console.log(this.a);
}
var obj2 = {
a: 42,
foo: foo
};
var obj1 = {
a: 2,
obj2: obj2
};
obj1.obj2.foo(); // 42
隐式丢失
有时隐式绑定的函数会丢失绑定对象、改用默认绑定:
function foo () {
console.log(this.a);
}
var obj = {
a: 2,
foo: foo
};
var bar = obj.foo; // 函数别名
var a = 1;
bar(); // 1
虽然bar是obj.foo的一个引用,但实际上它引用的是foo函数本身,因此此时的bar()是一个不带任何修饰的函数调用,因此应用了默认绑定规则。
传入回调函数时也会隐式丢失绑定对象:
function foo () {
console.log(this.a);
}
function doFoo (fn) {
// fn其实引用的是foo
fn(); //调用位置
}
var obj = {
a: 2,
foo: foo
};
var a = 1;
doFoo(obj.foo); // 1
setTimeout(obj.foo, 100); // 1
JavaScript环境中内置的setTimeout()函数实现和下面的代码类似:
function setTimeout (fn, delay) {
// 等待delay毫秒
fn(); // 调用位置
}
所以回调函数(如setTimeout里的回调函数)丢失this绑定是非常常见的。
function foo () {
console.log(this.a);
}
var obj = {
a: 2
};
foo.call(obj); // 2
通过foo.call(obj);,可以在调用foo时强制把它的this绑定到obj上。
如果你传入一个原始值(字符串类型,布尔类型或者数字类型)来当做this的绑定对象,这个原始值会被转换成它的对象形式(也就是new String(),new Boolean()或者new Number()),这通常被称为“装箱”。
但是显示绑定仍无法解决我们之前遇到的丢失绑定的问题,有2个方法可以解决:
function foo () {
console.log(this.a);
}
var obj = {
a: 2
};
var bar = function () {
foo.call(obj);
};
bar(); // 2
setTimeout(bar, 100); // 2
// 硬绑定的bar不可能再修改它的this
bar.call(window); // 2
bar函数内强制把foo的this绑定到了obj,无论之后如何调用函数bar,它总会在obj上调用foo。这种绑定是一种显式绑定,因此我们称之为硬绑定。
ES5种提供的Function.prototype.bind也是一种硬绑定。
Function.prototype.bind = function (obj) {
if (typeof this !== "function") {
throw new TypeError("Function.prototype.bind - what is trying to be bound is not callable");
}
var args = Array.prototype.slice.call(arguments, 1), // 截取参数
self = this, // 保存对象上下文
F = function () {},
fBound = function () {
return self.apply(
this instanceof F && obj // 1
? this
: obj || window,
args.concat(Array.prototype.slice.call(arguments)); // 将bind方法的参数和fBound方法的参数合并
);
}
F.prototype = this.prototype;
fBound.prototype = new F(); // 2
return fBound;
};
注意:绑定函数作为构造函数时,其this需继承自原函数,并且需要继承原函数的原型链方法,上述代码中的1和2处就是做这两件事。
function foo (el) {
console.log(el, this.id);
}
var obj = {
id: 'awesome'
};
// 调用foo时把this绑定到obj
[1,2,3].forEach(foo, obj); // 1 awesome 2 awesome 3 awesome
这些函数实际上就是通过call或者apply实现了显示绑定。
function foo (a) {
this.a = a;
}
var bar = new foo(2);
bar(); // 2
判断函数在某个位置应用的是哪条规则,可以按照下面的顺序来进行判断:
但是,有几个例外情况不适用上述4个规则:
function foo () {
console.log(this.a);
}
var a=2;
foo.call(null); // 2
function foo () {
console.log(this.a);
}
var a=2;
var o={a:3, foo:foo};
var p={a:4};
o.foo(); // 3
(p.foo = o.foo)(); // 2
赋值表达式p.foo = o.foo的返回值是目标函数的应用,因此调用位置是foo()而不是p.foo()或o.foo(),所以这里用了默认绑定。
上述的4条规则适用于普通正常函数,但是ES6给出了一种无法使用这些规则的特殊函数类型:箭头函数。箭头函数的this是根据外层(函数或者全局)作用域来决定的。
箭头函数的绑定无法被修改(new也不行),它本质上是用this的词法形式(根据当前的词法作用域来决定this,具体来说,箭头函数会继承外层函数调用的this绑定,这其实和我们常写的self = this;机制一样)替代this机制(取决于调用位置和条件)。
参考:《你不知道的JavaScript(上)》
我们知道,通过构造函数Vue就可以创建一个Vue的根实例,并启动Vue应用:
var app = new Vue({
el: ‘#app’,
data: myData
});
其中变量app就代表了这个Vue实例。
每个Vue实例创建时,都会经历一系列的初始化过程,同时也会调用相应的生命周期钩子,我们可以利用这些钩子,在合适的时机执行我们的业务逻辑。下图是官网的Vue生命周期示例图。
Vue生命周期,顾名思义,就是指Vue实例从创建到销毁的过程。我们来简单翻译下这张图:
注:上图来自https://www.cnblogs.com/fly_dragon/p/6220273.html
在上图中红色框中的钩子是Vue提供的可以注册的钩子,包括:
1.beforeCreate:在实例初始化之后,数据观测(Data Observer)和event/watch事件配置之前被调用;
2.created:该钩子在实例已经创建完成之后被调用。在这一步,实例已完成这些配置:数据(Data Observer)、属性和方法的运算,event/watch事件回调。但尚未挂载,实例存在、但$el还不可用(需要初始化处理一些数据时会比较常用这个钩子);
3.beforeMount:在挂载开始之前被调用,相关的render函数首次被调用;
4.mounted:el挂载到实例上后调用,一般我们的第一个业务逻辑会在这里开始;
5.beforeUpdate:数据更新时调用,发生在虚拟DOM重新渲染和打补丁之前。我们可以在这个钩子中进一步地更改状态,这不会触发附加的重新渲染过程;
6.updated:由于数据更改导致的虚拟DOM重新渲染和打补丁,在这之后会调用该钩子。当这个钩子被调用时,组件DOM已经更新,所以我们现在可以执行依赖于DOM的操作。然而在大多数情况下,我们应该避免在此期间更改状态,因为这可能会导致更新无限循环。该钩子在服务器端渲染期间不会被调用;
7.beforeDestroy:实例销毁之前调用,主要解绑一些使用addEventListener监听的事件等;
8.destroyed:实例销毁之后调用。调用之后,Vue实例指示的所有东西都会解绑,所有事件监听器都会被移除,所有的子实例也会被销毁。该钩子在服务端渲染期间不会被调用。
举一个简单的例子:
var app = new Vue({
el: '#app',
data() {
return {
name: 'Frida'
}
},
beforeCreate: function () {
console.log('创建前...')
console.log(this.name)
console.log(this.$el)
},
created: function () {
console.log('已创建')
console.log(this.name)
console.log(this.$el)
},
beforeMount: function () {
console.log('挂载之前')
console.log(this.name)
console.log(this.$el)
},
mounted: function () {
console.log('挂载完成')
console.log(this.name)
console.log(this.$el)
},
beforeUpdate: function () {
console.log('更新前')
console.log(this.name)
console.log(this.$el)
},
updated: function () {
console.log('更新完成')
console.log(this.name)
console.log(this.$el)
},
beforeDestroy: function () {
console.log('销毁前')
console.log(this.name)
console.log(this.$el)
},
destroyed: function () {
console.log('销毁之后')
console.log(this.name)
console.log(this.$el)
}
});
控制台打印结果:
接着在控制台修改data的值,控制台打印结果发生变化:
然后执行app.$destroy():
对以上过程进行总结:
注:上图来自https://www.cnblogs.com/gagag/p/6246493.html
此文仅是笔者在学习vue的过程中的学习笔记,我们仍需要在实践中不断深入学习相关知识点。
参考资料:
1.https://cn.vuejs.org/v2/guide/instance.html
2.Vue.js实战 梁灏
3.https://www.cnblogs.com/fly_dragon/p/6220273.html
4.https://www.cnblogs.com/gagag/p/6246493.html
2018年07月11日
需求:input输入框输入上限4个字节、达到上限则不能继续输入,其中1个英文表示1个字节、1个中文表示2个字节。
看到这个需求,第一个想到的就是input元素的maxlength属性。
MDN对input的maxlength属性的说明是:
如果 type 的值是 text, email, search, password, tel, 或 url,那么这个属性指明了用户最多可以输入的字符个数(按照Unicode编码方式计数);对于其他类型的输入框,该属性被忽略。它可以大于 size 属性的值。如果不指定这个属性,那么用户可以输入任意多的字符。如果指定为一个负值,那么元素表现出默认行为,即用户可以输入任意多的字符。本属性的约束规则,仅在元素的 value 属性发生变化时才会执行。译者注:ie10+
从中我们可以得知两个有用信息:
根据这两个信息,我们得到了实现此需求的基本方案:
在用户输入之后计算输入内容的字节数和剩余可输入字节数,并动态地改变input元素的maxlength属性值。
将输入内容的每一个中文字符替换成两个英文字符,计算其字符长度:
// 返回字符串str的长度,其中中文占2个长度单位,英文等字符占1个长度单位
let length = (str) => {
var r = /[^\x00-\xff]/g
return str.replace(r, 'mm').length
}思考解决方法过程中,分别实现过 通过@input事件触发方法来修改maxlength、把处理方法放到mixin里、封装一个处理方法的指令 3种方式,考虑可移植性及修改作用域字段的可行性,最终采用指令方式。
下面对主要逻辑进行说明:
maxlength:input元素maxlength属性值
limit:限制字节数
中文多消耗的字节数中文字符个数maxlength = limit - 中文多消耗的字节数 = limit - 中文字符个数
当连续输入的内容的字节数超过limit时,需要对内容进行截断:
截断长度 = 一个一个输入的非中文字符串长度 + 允许输入的中文字符串长度 = 非中文字符长度 + Math.floor((limit - 非中文字符所占字节数) / 2)
截断后内容 = 截断前内容.substring(0, 截断长度)
当在两个非中文之间(非末尾)输入超过限制的中文时,截取长度会多1个字节,需要再次校准输入内容:
校准后内容 = 校准前内容.substring(0, 截断长度 - 1)
vue自定义指令的钩子update是在VNode更新时调用,所以我们的处理方法在update钩子中进行;
vue自定义指令钩子函数会被传入参数el、binding、vnode、oldVnode。我们可以通过el拿到指定绑定的DOM;通过binding拿到指令的绑定值和传入的参数等等;通过vnode可以拿到vue编译生成的虚拟节点,其中vnode.context是虚拟节点上下文、也就是this,通过它我们可以改变指令所在组件data的任一变量。
具体代码和使用说明见vue_input_maxlength。
input v-model 使用 computed
<el-input v-model="content"></el-input>
export default {
data () {
return {
contentStore: ''
}
},
computed: {
content: {
get () {
return this.contentStore
},
set (val) {
this.contentStore = maxlength(val, 4) // maxlength是截取字符串方法
}
}
}
}问题:虽然变量长度被限制了,但输入框仍可继续输入。

打印input元素的value,得到:
双向数据绑定失效了。
从v-model双向数据绑定原理入手
方法1中双向数据绑定失效了,那么我们来研究下input双向数据绑定的实现原理,看看能否找到突破口。
input的v-model只是一个简化的指令,它的双向数据绑定原理如下:
<input v-model="msg">
<!-- 相当于 -->
<input :value="msg" @input="e => msg = e.target.value">
<textarea v-model="msg"></textarea>
<!-- 相当于 -->
<textarea :value="msg" @input="e => msg = e.target.value"></textarea>改写双向数据绑定方法:
<el-input :value="contentStore" @input.native="maxlengthInput">
methods: {
maxlengthInput (e) {
this.contentStore = maxlength(e.target.value, 4) // maxlength是截取字符串方法
}
}结果和方法1一样,输入框仍可继续输入。
这里input的value是根据contentStore进行改变的,那直接修改DOM是否可行呢?
直接修改DOM的value值
在方法2的基础上,修改maxlengthInput方法,通过DOM操作来直接修改input的value,并打印出input的value进行观察:
<el-input @input.native="maxlengthInput">
methods: {
maxlengthInput (e) {
let value = maxlength(e.target.value, 4)
this.contentStore = value
document.querySelector('.el-input__inner').value = value
console.log(document.querySelector('.el-input__inner').value)
}
}
根据打印出来的内容可以看到,实际上input的value被改变了,而输入框内仍可正常输入,原因可能是element-ui的<el-input>处理顺序问题(用原生input元素没有这个问题),那我们把dom赋值操作延后到下一个tick:
maxlengthInput (e) {
let value = maxlength(e.target.value, 4)
this.contentStore = value
setTimeout(() => {
document.querySelector('.el-input__inner').value = value
console.log(document.querySelector('.el-input__inner').value)
}, 0)
}结果是可行的:

所以结束了吗?来输入中文试试:


中文输入法的每个拼音字母都被认为是一个有效的输入,这个缺陷是致命的。
compositionend事件
输入中文时,会先后触发compositionstart(输入中文前)、compositionend(中文输入完成后)事件。所以可以利用compositionend事件解决方法3的问题。
但是,删除输入内容时是无法触发compositionend事件的,那么,就需要同时监听input事件。
input事件会比compositionend事件先触发,所以会出现方法3的无法输入中文的问题,不过只要把input事件处理延迟到compositionend之后(比如用setTimeout),这个问题也可以解决。随之而来的问题就是输入非中文字符时,input事件处理也会延迟,用户体验不太友好。
对于区分中英文来限制输入框输入长度的需求,利用input元素的maxlength属性是比较便利和可行的方式;使用vue自定义指令可以提高方法的可用性(再把指令封装成插件,可以很大地提高方法的可移植性)。
当然,vue自定义指令方法有一个问题,当在非末尾输入超过limit的内容时,会截断末尾的字符、而不是截断正在输入的内容。解决这个问题需要比较输入前和输入后的字符串、再把diff出的字符串截断掉。虽然这个问题可以解决,但性价比不高,对于当前的需求也没有解决的必要。
我在工程中搜索@font-face,然后找到了两个:8bit Art Sans和VT323。
glyphhanger http://make8bitart.localhost/ --US_ASCII --subset=assets/fonts/*.ttf
<link rel="preload" href="FILE_PATH.woff2" as="font" type="font/woff2" crossorigin>

(chrome浏览器,选择Fast 3G网络环境)
我们来比较下做了以上操作之前和之后页面的加载情况
之前
之后
字体加载有时候会让人感到困惑甚至恐惧,如果你正在被字体加载问题困扰的话,以上内容能帮助你快速提高你的网站的性能,或许不能做到性能最优、但能让你的网站性能变得更好。
通过使用preload,在Fast 3G网络环境下,我们消除了FOUT和FOIT。在更慢的网络环境中,我们在浏览器中使用font-display,以消除FOIT、使浏览器显示降级字体(FOUT)。
原文:23 MINUTES OF WORK FOR BETTER FONT LOADING
译者注:
2019年01月16日
DOM结构:
<div class="parent">
<div class="child">DEMO</div>
</div>注:下文的“容器”在不特殊说明情况下都是指目标容器,即我们想让其居中的目标元素(class为child的div)。
一、单行文本
设置line-height等于height。
二、容器高度固定
Negative margins(负外边距)
.parent{
height: 100%;
position: relative;
}
.child{
height: 50px; // 容器高度固定
position: absolute;
top: 50%;
margin-top: -25px;
}Absolute Centering(绝对居中)
.parent{
height: 100%;
position: relative;
}
.child{
height: 50px;
position: absolute;
top: 0;
bottom: 0;
margin: auto 0;
}插入额外元素
<div class="parent">
<!-- 在child前插入brother -->
<div class="brother"></div>
<div class="child">DEMO</div>
</div>.parent{
height: 100%;
}
.brother{
height: 50%;
margin-bottom: -25px;
}
.child{
height: 50px;
}三、容器高度不定
table-cell + vertical-align
.parent{
height: 100px;
display: table-cell;
vertical-align: middle;
}absolute + transform
.parent{
height: 100%;
position: relative;
}
.child{
position: absolute;
top: 50%;
-webkit-transform: translateY(-50%);
-moz-transform: translateY(-50%);
-ms-transform: translateY(-50%);
-o-transform: translateY(-50%);
transform: translateY(-50%);
}优点:根据自身高度偏移,所以不需要指定容器高度;
缺点:要适配各种浏览器;IE8及以下不支持。
flex + align-items
.parent{
height: 100%;
display: flex;
align-items: center;
}以上样式的兼容版:
.parent{
height: 100%;
display: -webkit-box; /* OLD - ios 6-, Safari 3.1-6 */
display: -moz-box; /* OLD - Firefox 19- (buggy but mostly works) */
display: -ms-flexbox; /* TWEENER - IE 10 */
display: -webkit-flex; /* NEW - Chrome */
display: flex; /* NEW - Spec - Opera 12.1, Firefox 20+ */
-webkit-box-align: center; /* 09版 */
-webkit-box-pack: center; /* 12版 */
-moz-box-pack: center;
-ms-flex-align: center; /* IE 10 */
-webkit-align-items: center;
-moz-align-items: center;
align-items: center;
}
inline-block + vertical-align + 伪元素
.parent:before{
content: '';
display: inline-block;
height: 100%;
vertical-align: middle;
margin-left: -0.5em;
}
.child{
display: inline-block;
vertical-align: middle;
max-width: 100%;
}注:
font-size设置的是字体的高度,宽度要根据具体字符而定,英文字符0.5em,中文字符是宽高一致的、所以是1em。content:’’;会占0.5em;
如果不用margin-left:-0.5em;也可以:
.parent{
font-size: 0;
}
.child{
font-size: 16px;
}这里.child必须设置max-width:100%;因为如果child超过parent宽度,child会被挤到底部。
一、容器宽度固定
block + margin:0 auto
.child{ /* .child是block元素 */
width: 100px;
margin: 0 auto;
}二、容器宽度不定的情况
inline-block + text-align
.parent{
text-align: center;
}
.child{
display: inline-block;
}注:inline-block元素宽度根据内容决定,block元素宽度撑满父元素。
table + margin
.child{
display: table;
margin: 0 auto;
}注:
absolute + transform
.parent{
position: relative;
}
.child{
position: absolute;
left: 50%;
-webkit-transform: translateX(-50%);
-moz-transform: translateX(-50%);
-ms-transform: translateX(-50%);
-o-transform: translateX(-50%);
transform: translateX(-50%);
}注:absolute后元素宽度由内容决定。
margin + transform
.child{
margin-left: 50%;
transform: translateX(-50%);
}flex + justify-content
父元素是flex,子元素自然是flex-item,flex-item默认情况下宽度为内容宽度。
1)方案一
.parent{
display: flex;
justify-content: center;
}2)方案二
.parent{
display: flex;
}
.child{
margin: 0 auto;
}综上,在容器宽高未知时,设置水平、垂直居中的方案有:
当然还有其他方法(有空再学习总结下):
2019年01月23日
首先简要介绍下Event Loop、Promise和async/await:
Event Loop
我们知道Event Loop(事件循环)总是先执行macrotask(宏任务),然后执行microtask(微任务),在执行完所有微任务后,一轮事件循环就结束了。接下来再执行macrotask、microtask,如此循环往复;
每一个任务的执行,无论是macrotask还是microtask,都是借助函数调用栈来完成;
macrotask主要包括:script(整体代码)、setTimeout、setInterval、I/O、UI交互事件、setImmediate(Node.js环境);
microtask主要包括:Promise、MutationObserver、process.nextTick(Node.js环境)。
setTimeout/Promise等我们称之为任务源,而进入任务队列的是它们指定的具体执行任务;
// setTimeout中的回调函数才是进入任务队列的任务
// setTimeout作为一个任务分发器,这个函数会立即执行,而它所要分发的任务,也就是它的第一个参数,才是延迟执行的(这里setTimeout第2个参数默认为0,所以延迟0ms执行)
setTimeout(function() {
console.log('123');
})关于Event Loop可以参考这几篇文章(你不得不知的Event Loop、前端基础进阶(十二):深入核心,详解事件循环机制、从event loop到async await来了解事件循环机制),这里不再详细介绍。
Promise
Promise对象有3种状态:pending(进行中)、fulfilled(已成功)、rejected(以失败)。
Promise对象的状态改变,只有两种可能:从pending变为fulfilled 和 从pending变为rejected。只要这两种情况发生了,状态就凝固了,不会再变了,会一直保持这个结果,这时就称为 resolved(已定型)。
new Promise(function(resolve){
console.log('1');
resolve();
}).then(function(){
console.log('2')
})上述Promise构造函数的第一个参数进入函数调用栈执行(console.log('1');和resolve(););resolve();之后,后面的.then被分发到microtask队列中去。
async/await
async函数返回一个Promise对象,可以使用then方法添加回调函数。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成(fulfilled),再接着执行函数体内后面的语句;
async内部如果没有主动return Promise,那么async会把函数的返回值用Promise包装;
正常情况下,await命令后面是一个Promise对象,返回该对象的结果。如果不是Promise对象,就直接返回对应的值;(另一种情况是,await命令后面是一个thenable对象(即定义了then方法的对象,如await new Sleep(1000);),那么await会将其等同于Promise对象。)
遇到await关键字,await右边的语句会被立即执行,然后await下面的代码进入等待状态,等待await得到的结果。也就是如果await后面不是Promise对象,那么await直接得到结果(可以理解为await后面的内容fulfilled)、await后面的代码进入microtask队列;如果await后面是Promise对象,则会执行这个Promise、等待这个Promise对象fulfilled,再把Promise对象resolve的参数作为await表达式的结果、后面代码进入microtask队列。
可以看出,async函数返回的Promise对象是fulfilled(上图中的resolved)或rejected(上图中的rejected)。
从一个题目说起
async function a1 () {
console.log('a1 start')
await a2()
console.log('a1 end')
}
async function a2 () {
console.log('a2')
}
console.log('script start')
setTimeout(() => {
console.log('setTimeout')
}, 0)
Promise.resolve().then(() => {
console.log('promise1')
})
a1()
let promise2 = new Promise((resolve) => {
resolve('promise2.then')
console.log('promise2')
})
promise2.then((res) => {
console.log(res)
Promise.resolve().then(() => {
console.log('promise3')
})
})
console.log('script end')所以上述代码的执行过程是:
补充说明:
那么来运行下上述代码,看看结果是否跟我们分析的一致。
在node环境里运行上述代码,输出结果和分析的一致:
在chrome浏览器运行:
promise2.then和promise3先于a1 end打印输出了。这是怎么回事?
查了很多文章都没有看到合理的解释,直到看到知乎上贺老的这个回答。
async function f() {
await p
console.log('ok')
}
// 可以理解为:
function f() {
return RESOLVE(p).then(() => {
console.log('ok')
})
}这里 RESOLVE(P) 接近于 Promise.resolve(p),当p本身已经是Promise实例、那么这里RESOLVE(p)会直接返回p而不是产生一个新的Promise。老版本V8(node环境)的问题是,当p是一个已经fulfilled的Promise(这里直接返回非Promise的p相当于fulfilled),会进行激进优化,导致.then立即进入microtask队列;而如果RESOLVE(p)严格按照标准,也就是进入队列的是Promise的resolve过程,那么该Promise的then不会立即调用,而是要等到当前microtask队列执行到当前resolve过程才会被调用、然后其回调(也就是await后面的语句)才会进入microtask队列。
注意,这里setImmediate指node环境的setImmediate,而不是浏览器环境的window.setImmediate。
async/await和Promise顺序的问题终于弄明白了,开心~
setImmediate(function() {
console.log('immediate1');
process.nextTick(function() {
console.log('immediate1_nextTick');
})
new Promise(function(resolve) {
console.log('immediate1_promise');
resolve();
}).then(function() {
console.log('immediate1_then')
})
})
setTimeout(function() {
console.log('timeout1');
process.nextTick(function() {
console.log('timeout1_nextTick');
})
new Promise(function(resolve) {
console.log('timeout1_promise');
resolve();
}).then(function() {
console.log('timeout1_then')
})
}, 3)
process.nextTick(function() {
console.log('outer_nextTick');
})
new Promise(function(resolve) {
console.log('outer_promise');
resolve();
}).then(function() {
console.log('outer_then')
})结果如下:
按理说setImmediate 1任务源先分发任务、timeout 1后分发任务(执行顺序在后,而且延迟3ms分发),那么应该先执行setImmediate 1任务源分发的代码呀?怎么时而setImmediate 1先输出、时而timeout 1先输出?
直到看到这篇文章,才明白原来不同任务源有自己的任务队列,队列执行有优先级。比如:
nextTick队列会比Promise先执行。nextTick中的可执行任务执行完毕之后,才会开始执行Promise队列中的任务。
setImmediate的任务队列会在setTimeout队列的后面执行。
只有当setTimeout中所有的任务执行完毕之后,才会再次开始执行微任务队列。并且清空所有的可执行微任务。
setTiemout队列产生的微任务执行完毕之后,循环则回过头来开始执行setImmediate队列。仍然是先将setImmediate队列中的任务执行完毕,再执行所产生的微任务。
当我们在执行setTimeout任务中遇到setTimeout时,它仍然会将对应的任务分发到setTimeout队列中去,但是该任务就得等到下一轮事件循环执行了。
例子:
setImmediate(function() {
console.log('immediate1');
process.nextTick(function() {
console.log('immediate1_nextTick');
})
new Promise(function(resolve) {
console.log('immediate1_promise');
resolve();
}).then(function() {
console.log('immediate1_then')
})
})
setTimeout(function() {
console.log('timeout1');
process.nextTick(function() {
console.log('timeout1_nextTick');
})
new Promise(function(resolve) {
console.log('timeout1_promise');
resolve();
}).then(function() {
console.log('timeout1_then')
})
setTimeout(function() {
console.log('timeout inner');
})
})
process.nextTick(function() {
console.log('outer_nextTick');
})
new Promise(function(resolve) {
console.log('outer_promise');
resolve();
}).then(function() {
console.log('outer_then')
})
setTimeout(function() {
console.log('timeout2');
process.nextTick(function() {
console.log('timeout2_nextTick');
})
new Promise(function(resolve) {
console.log('timeout2_promise');
resolve();
}).then(function() {
console.log('timeout2_then')
})
})结果:
这里只能保证timeout inner在timeout队列执行完后再执行,但其和immediate队列的顺序不可预测。【好吧,我承认我累了,没有力气再挖下去了。
在我看来,既然是异步,那么就不用太在意其执行顺序了(真那么在意顺序的话,为什么不直接用同步操作?)。
补充一篇可以参考的文章:
https://juejin.im/post/5c394da4518825253661bd4d
NEI(Netease Easy Interface) 是一个为我们提供接口约定、维护的接口管理平台,它同时提供了自动化构建工具。
简单介绍下NEI常用的几个功能:

nei build -k xyznei build 构建的项目:nei updatenei server// package.json
"scripts": {
"dev": "node build/dev-server.js"
}// build/dev-server.js
var express = require('express')
var app = express()
app.use(require('./../mock')// /mock/index.js
var fs = require('fs')
var path = require('path')
var stripJsonComments = require('strip-json-comments')
var resolveMockDataPath = function(mockDir, filePath) {
if (filePath.indexOf('/') === 0) {
filePath = filePath.slice(1, filePath.length)
}
return path.resolve(mockDir, filePath)
}
var readFile = function(extname) {
extname = extname || '.json'
return function(filePath) {
filePath += extname
let exists = fs.existsSync(filePath)
if (exists) {
return fs.readFileSync(filePath, 'UTF-8')
}
return exists
}
}
var readJSONFile = readFile()
var readMockData = function(filePath) {
return readJSONFile(filePath)
}
var mockDir = path.resolve(__dirname, '../mock')
var getFilePath = require('./mockRouterMap').getFilePath
var initMockMiddleware = function(request, response, next) {
var requestPath = request.path
var method = request.method.toLowerCase()
let mockDataPath = getFilePath(requestPath, method, request.xhr)
if (mockDataPath) {
let content = readMockData(resolveMockDataPath(mockDir, mockDataPath))
if (content) {
response.status(200).json(JSON.parse(stripJsonComments(content)))
} else {
var NO_FOUND_CODE = 404
response.json(NO_FOUND_CODE, {
code: NO_FOUND_CODE,
msg: '接口数据未定义'
})
}
} else {
next()
}
}
module.exports = initMockMiddleware// mockRouterMap.js
const path2Regexp = require('path-to-regexp')
const MOCK_DATA_DIR = './data'
const initMockRouterReg = function (map) {
var regMap = new Map()
for (var pathReg in map) {
var keyArr = map[pathReg].split(/\s/)
var pathInfo = {}, urlReg
if (keyArr.length > 1) {
urlReg = keyArr[1]
pathInfo.method = keyArr[0].toLowerCase()
} else {
urlReg = keyArr[0]
}
pathInfo.mockFile = MOCK_DATA_DIR + map[pathReg]
regMap.set(path2Regexp(urlReg), pathInfo)
}
return regMap
}
var routeMap = {
'get /api/user/userInfo': '/api/user/userInfo', // 用户信息
'post /api/novel/list': '/api/novel/list', // 长文-已发布列表
'post /api/novel/listDraft': '/api/novel/listDraft', // 长文-草稿列表
'post /api/novel/edit/*': '/api/novel/edit', // 长文-编辑
'post /api/novel/edit/10086/1': '/api/novel/edit/10086/1', // 长文-编辑-草稿
'post /api/novel/edit/10086/2': '/api/novel/edit/10086/2', // 长文-编辑-长文
'post /api/novel/delete': '/api/novel/delete', // 长文-删除草稿
'post /api/novel/save': '/api/novel/save', // 长文-保存草稿
'post /api/img/upload': '/api/img/upload', // 上传图片
'post /api/article/goodsInfo': '/api/article/goodsInfo', // 长文-获取商品信息
'post /api/novel/user': '/api/novel/user', // 长文-获取用户信息
'post /api/novel/article': '/api/novel/article', // 长文-获取用户信息
'get /api/novel/cell/permission': '/api/novel/cell/permission' // 长文-获取用户权限
}
const pathRegMap = initMockRouterReg(routeMap)
module.exports = {
getFilePath (requestPath, method, isXhr) {
var filePath = false
pathRegMap.forEach(function (pathInfo, urlReg) {
var limitMethod = pathInfo.method
if (urlReg.test(requestPath)) {
filePath = pathInfo.mockFile
if (limitMethod && limitMethod !== method && isXhr) {
filePath = false
}
}
})
return filePath
}
}从上面代码可以看出,该方案使用本地mock文件存放接口的返回数据。其缺点非常明显:
NEI作为一个定义、维护接口的平台,使用方便、非常便于接口管理。另外,QA使用的接口测试平台gotest与NEI对接,这就要求开发必须在NEI上维护接口约定。
那么如何把NEI与原有mock方案有机地结合起来呢?
社区后台的解决方案是:使用原有中间件,利用NEI提供的mock数据和自动化构建方案替换原来的手动mock(包括手动创建mock文件和数据、手动维护接口和mock文件的对应关系)方式,并增加使用线上NEI提供的mock数据功能 和 代理到线上/测试环境的功能。
// /mock/proxy.config.js
const proxy = require('http-proxy-middleware')
const NO_NEED_PROXY = process.env.NO_NEED_PROXY
const proxyTarget = 'http://content-kl.netease.com'
const proxyTable = NO_NEED_PROXY ? [] : [
proxy('/api', {
target: proxyTarget,
changeOrigin: true,
}),
proxy('/community', {
target: proxyTarget,
changeOrigin: true,
})
]
module.exports = {
// 项目的nei唯一标识
key: '07841b89b63b942b1bb0abcfd090685d',
// 是否使用 nei 提供的在线 mock 数据
neiOnline: true,
// 是否代理到测试/线上环境,只有当neiOnline为false时才有效:true - 代理到proxy target,false - 使用本地mock数据
useProxy: false,
// 代理环境配置
proxyTable
}// build/dev-server.js
const { neiOnline, useProxy, proxyTable } = require(path.resolve(__dirname, './../mock/proxy.config.js'))
var express = require('express')
var app = express()
if (neiOnline) {
console.log('use nei mock data online')
app.use(require('./../mock/nei-online.js'))
} else if (useProxy && proxyTable.length >= 0) {
console.log('use proxy')
app.use(proxyTable)
} else {
console.log('user local mock')
app.use(require('./../mock'))
}nei本身提供了使用nei在线mock数据的方法:nei server可以启动本地模拟容器,设置 server.config.js 文件的 online: true就可以使用nei提供的在线mock数据了。
那么不使用nei server,该怎么实时拿到nei线上mock数据呢?剖析nei-toolkit源码,发现nei上定义的每个接口都可以通过https://nei.netease.com/api/mockdata?path=${requestPath}&type=3&key=${项目key}&method=${method}请求来返回结果数据。(其中requestPath是接口url,type为3表示api接口、1表示页面接口,key是项目唯一标识码,method是请求方法如get或post)
所以我们方案是:
// /mock/nei-online.js
const querystring = require('querystring')
const path = require('path')
const os = require('os')
const exec = require('child_process').exec
const { key } = require('./proxy.config')
const globule = require('globule')
const neiBaseDir = path.resolve(os.homedir(), 'localMock', key)
const neiServerConfigFolder = path.resolve(neiBaseDir, './nei**')
let configPathArr = globule.find(neiServerConfigFolder)
let neiServerConfig = path.resolve(configPathArr[0], './server.config.js')
let lock = false
let reloadServerConfig = () => {
if (lock) {
return
}
lock = true
// 只需要更新server.config.js文件(nei线上发生改变[添加、删除接口],
// nei update或nei update -w都会获得最新server.config.js文件)
console.log('reload server config start')
const neiBuild = `nei build -k ${key} -o ${neiBaseDir}`
const neiUpdate = `cd ~/localMock/${key} && nei update`
const cmdStr = (configPathArr && configPathArr.length) ? neiUpdate : neiBuild
exec(cmdStr, (error, stdout, stderr) => {
if (error) {
console.log('cmd exec error:', error)
console.log('cmd exec stdout:', stdout)
console.log('cmd exec stderr:', stderr)
return
}
console.log('reload success')
lock = false
})
}
const initMockRouterReg = function (map) {
var regMap = new Map()
for (var pathReg in map) {
let url = pathReg.split(' ')[1]
var content = map[pathReg]
var pathInfo = {}
pathInfo.method = pathReg.split(' ')[0].toLowerCase()
pathInfo.id = content.id
regMap.set(url, pathInfo)
}
return regMap
}
let existUrlAndGetId = (requestPath, method, isXhr) => {
let { routes } = require(neiServerConfig)
let pathRegMap = initMockRouterReg(routes)
let existUrl = false
let id = null
pathRegMap.forEach(function (pathInfo, url) {
let limitMethod = pathInfo.method
if (url === requestPath) {
existUrl = true
id = pathInfo.id
if (limitMethod && limitMethod !== method && isXhr) {
existUrl = false
}
}
})
return { existUrl, id }
}
var getFromNEISite = (requestPath, method, id, callback) => {
let params = {
path: requestPath,
type: 3, // api代理:3,页面代理:1
key: key,
id,
method: method
}
let url = 'https://nei.netease.com/api/mockdata?' + querystring.stringify(params)
require('https').get(url, function (res) {
let ret = []
res.on('data', function (chunk) {
ret.push(chunk.toString())
})
res.on('end', function () {
let json = null
try {
json = JSON.parse(ret.join(''))
} catch (ex) {
// ignore
}
if (json && json.code === 200) {
// 成功
if (json.result.error.length) {
console.log(`错误: ${json.result.error.map(err => err.message).join(', ')}`)
}
// 真正的 mock 数据
callback(json.result.json)
} else {
callback(ret.join(''))
}
})
}).on('error', function (error) {
callback(error.message)
})
}
var neiOnlineMockMiddleware = (request, response, next) => {
let requestPath = request.path
let method = request.method.toLowerCase()
// 实时获取nei线上接口信息
reloadServerConfig()
let { existUrl, id } = existUrlAndGetId(requestPath, method, request.xhr)
if (existUrl) {
getFromNEISite(requestPath, method, id, (json) => {
if (json) {
response.status(200).json(json)
} else {
var NO_FOUND_CODE = 404
response.json(NO_FOUND_CODE, {
code: NO_FOUND_CODE,
msg: '接口数据未定义'
})
}
})
} else {
next()
}
}
module.exports = neiOnlineMockMiddleware原有的本地mock方案,是根据请求和mock文件的对应关系去取/mock/data下的相应mock文件,那么我们可以根据nei提供的mock文件替换掉/mock/data下的文件,根据server.config.js自动生成接口和mock文件对应关系routeMap,从而将原有本地mock中间件与NEI有机结合起来。
// package.json
"scripts": {
"mock": "NO_NEED_PROXY=true node mock/nei-mock.js"
}// /mock/nei-mock.js
const exec = require('child_process').exec
const fs = require('fs')
const path = require('path')
const os = require('os')
const globule = require('globule')
const yargs = require('yargs')
const rimraf = require('rimraf')
const async = require('async')
const { key } = require('./proxy.config')
// 命令行参数
let argv = yargs
.option('f', {
alias: 'force',
describe: 'force to pull data from nei',
boolean: true,
default: false
})
.help('h')
.alias('h', 'help')
.alias('v', 'version')
.version('0.0.1')
.usage('Usage: hello [options]')
.example('npm run mock, npm run mock -- -f, npm run mock -- --force')
.argv
const neiBaseDir = path.resolve(os.homedir(), 'localMock', key)
const copyTar = path.join(__dirname, './../mock/data')
// 判断文件/文件夹是否已存在
function fsExistsSync (path) {
try {
fs.accessSync(path, fs.F_OK)
} catch (e){
return false
}
return true
}
// 复制文件
let copyFile = (src, tar, cb) => {
console.log('file update:', tar)
let rs = fs.createReadStream(src)
rs.on('error', (error) => {
if (error) {
console.log('file read error:', src)
}
cb && cb(error)
})
let ws = fs.createWriteStream(tar)
ws.on('error', (error) => {
if (error) {
console.log('file write error:', tar)
}
cb && cb(error)
})
ws.on('close', (ex) => {
cb && cb(ex)
})
rs.pipe(ws)
}
// 复制文件夹
let copyFolder = (srcDir, tarDir, cb) => {
fs.readdir(srcDir, (error, files) => {
if (error) {
console.log('readdir error:', error)
cb && cb(error)
return
}
files.forEach((file) => {
let srcPath = path.join(srcDir, file)
let tarPath = path.join(tarDir, file)
fs.stat(srcPath, (error, stats) => {
if (error) {
console.log('stat error:', error)
return
}
if (stats.isDirectory()) {
console.log('mkdir:', tarPath)
fs.mkdir(tarPath, (error) => {
if (error && error.code !== 'EEXIST') {
console.log('mrdir error:', error)
return
}
// 无异常 或 已经存在的文件夹(error.code === 'EEXIST'),复制文件夹内容
copyFolder(srcPath, tarPath, cb)
})
} else if (file === 'data.json') {
// 是文件,且文件名是 data.json
let newTarDir = tarDir + '.json'
if (!fsExistsSync(newTarDir)) {
copyFile(srcPath, newTarDir, cb)
} else {
console.log('file exist:', newTarDir)
}
// 删除data.json的上一级目录
rimraf(tarDir, (error) => {
if (error) {
console.log('rmdir error:', error)
return
}
})
}
})
})
// 为空时直接回调
files.length === 0 && cb && cb('files is empty')
})
}
let createMockData = (neiBaseDir) => {
const copySrcGET = path.join(neiBaseDir, './mock/get')
const copySrcPOST = path.join(neiBaseDir, './mock/post')
copyFolder(copySrcGET, copyTar, (error) => {
if (error) {
console.log('copy get error:', error)
return
}
})
copyFolder(copySrcPOST, copyTar, (error) => {
if (error) {
console.log('copy post error:', error)
return
}
})
}
// 从nei的server.config.js提取route map
let routeMap = (folderPath) => {
let srcPath = path.resolve(folderPath, './server.config.js')
let tarPath = path.join(__dirname, './routeMap.json')
let serverContent = require(srcPath)
let { routes } = serverContent
// 将格式化后的数据写入tarPath所在文件
fs.writeFile(tarPath, formatRoutes(routes), (error) => {
if (error) {
console.log('write file error:', error)
return
}
console.log('update route map: success')
})
}
// format server.config.js 的 routes,返回格式化后的对象
let formatRoutes = (routes) => {
let result = {}
for (let key in routes) {
result[key] = key.split(' ')[1]
}
// JSON.stringify后两个参数可以让json文件换行、4空格缩进 格式化显示
return JSON.stringify(result, null, 4)
}
let softUpdate = (cb) => {
const neiServerConfig = path.resolve(neiBaseDir, './nei**')
let configPathArr = globule.find(neiServerConfig)
// 从nei拉取mock数据
const neiBuild = `nei build -k ${key} -o ${neiBaseDir}`
// nei update: 更新接口文件,但本地已存在的不覆盖;
// nei update -w: 覆盖已存在的文件,但本地已存在、nei已删除的文件不处理(需要用户手动删除)。
// const neiUpdate = `cd ~/localMock/${key} && nei update -w`
const neiUpdate = `cd ~/localMock/${key} && nei update`
const cmdStr = (configPathArr && configPathArr.length) ? neiUpdate : neiBuild
console.log('nei exec start:', cmdStr)
// 每次执行命令,总是先 nei build 或 nei update,然后更新本地的数据
exec(cmdStr, (error, stdout, stderr) => {
console.log('nei exec end')
if (error) {
cb && cb('cmd exec error')
console.log('cmd exec error:', error)
console.log('cmd exec stdout:', stdout)
console.log('cmd exec stderr:', stderr)
return
}
!configPathArr[0] && (configPathArr = globule.find(neiServerConfig))
routeMap(configPathArr[0])
createMockData(neiBaseDir)
cb && cb()
})
}
// 删除 ~/localMock/${key}文件
let removeLocalMock = (cb) => {
console.log('remove localMock start:', neiBaseDir)
rimraf(neiBaseDir, (error) => {
if (error) {
cb && cb('remove localMock error')
console.log('remove localMock error:', error)
return
}
console.log('remove localMock end')
cb && cb()
})
}
// 删除本工程mock/data下的文件
let removeProjectMockData = (cb) => {
console.log('remove project mock data start')
fs.readdir(copyTar, (error, files) => {
if (error) {
cb && cb('remove project mock data readdir error')
console.log('readdir error:', error)
return
}
files.forEach((file) => {
let theFolder = path.join(copyTar, file)
rimraf(theFolder, error => {
if (error) {
cb && cb('remove project mock data error')
console.log('remove project mock data error:', error)
return
}
console.log('remove project mock data end')
})
})
// 为空时直接回调
files.length === 0 && console.log('project mock data is empty')
cb && cb()
})
}
let hardUpdate = () => {
async.series([
removeLocalMock, // 删除 ~/localMock/${key}文件
removeProjectMockData, // 删除本工程mock/data下的文件
softUpdate // 重新拉取
],
(err, results) => {
if (err) {
console.log('async series error:', err)
}
})
}
let main = () => {
if (argv.f) {
// 强制从nei拉取数据、覆盖本地mock数据
hardUpdate()
} else {
// 更新nei新增接口、保留本地mock数据
softUpdate()
}
}
main()注意:nei拉取到本地的文件结构是在nei工程规范中定义的。
mockRouterMap.js文件修改(只贴出修改的代码):
// mockRouterMap.js
const fs = require('fs')
const path = require('path')
const ROUTE_MAP = './routeMap.json'
// 删除原先的routeMap
let routeMapPath = path.join(__dirname, ROUTE_MAP)
let routeMap = JSON.parse(fs.readFileSync(routeMapPath))通过http-proxy-middleware把请求代理转发到其他服务器,从而响应得到其他服务器上该请求的返回数据。
关键代码:
// mock/proxy.config.js
const proxy = require('http-proxy-middleware')
const proxyTarget = 'http://content-kl.netease.com'
const proxyTable = [
proxy('/api', {
target: proxyTarget,
changeOrigin: true,
}),
proxy('/community', {
target: proxyTarget,
changeOrigin: true,
})
]
module.exports = {
// 代理环境配置
proxyTable
}// build/dev-server.js
const { proxyTable } = require(path.resolve(__dirname, './../mock/proxy.config.js'))
app.use(proxyTable)当我们需要定位线上或测试环境的问题时,通常的做法是拦截资源请求、使其走本地资源(如使用Fiddler),这样就可以在本地定位问题了。社区组娄涛同学写了个proxy-local(github),可以在不使用代理工具的情况下让线上/测试环境请求本地资源。
我们拿到一个需求之后,为了达到前后端分离的高效开发方式,开发各阶段都需要不同的数据mock方式。
2019年05月23日
状态管理工具系列文章——理论篇
[TOC]
上学的时候(2010-2016),说起架构模式,就是MVC。虽然现在前端已经不大提MVC了,但是追根溯源,我们还是得从它谈起。

MVC将业务数据(Model)与用户界面(View)隔离,用控制器(Controller)管理逻辑和用户输入。
在实际开发中,当项目越来越大、逻辑越来越复杂时,可能会出现多个View对应多个Model。
图2. MVC的问题
多个View对应多个Model,就导致了数据流动方式的混乱。
以Backbone为例,由于Model对外直接暴露了set和on方法,导致View层可以随意改变Model中的值,也可以随意监听Model中值的变化。这样的设定最终会导致一个庞大的Model中的某个字段变化后,可能触发无数个change事件。在这些change事件的回调中,可能还有新的set方法调用,导致更多的change事件触发。
更糟糕的是,一个Model还能改变另一个Model的值,整个数据流动的方式变得更加混乱,不可捉摸。
为了解决MVC的问题,Flux应运而生。
Flux是一套基于dispatcher的前端应用架构模式,其核心**是数据和逻辑永远单向流动。
图3. Flux模型
Dispatcher是Flux中的核心概念,它有2个API:
所有的请求和改变都只能通过action发出,统一由Dispatcher来分配。
Store负责保存数据,并定义修改数据的逻辑;它调用Dispatcher的register方法将自己注册为一个监听器,这样每当使用Dispatcher的dispatch方法分发一个action时,Store注册的监听器就会被调用。
在Flux中,Store只对外暴露getter(读取器)而不暴露setter(设置器),这意味着在Store之外只能读取Store中的数据而不能进行任何修改。
对于View,如果界面操作需要修改数据,则必须使用Dispatcher分发一个action。
这样,就保证了数据和逻辑的单向流动。
各个角色之间不会像前端MVC模式那样存在交错的连线,Store中的数据的变化不再混乱。
Flux是一种架构**,有很多对Flux**的不同实现。
Redux把自己定位为一个"可预测的状态容器"。它遵循Flux**的**"严格的单向数据流"**。
图4. Redux的核心运作流程
action:action是通过JavaScript普通对象来描述的;它是store数据更新的唯一来源,一般会通过store.dispatch()将action传到store;
Reducer:Reducers指定了应用状态的变化如何响应actions并发送到store(action和store之间的桥梁),即action描述有事件发生、Reducer描述如何更新state;
// reducer就是一个纯函数,接收旧的state和action,返回新的state
(previousState, action) => newState;
Store(state):Redux应用只有一个单一的store,需要拆分时是通过reducer组合(combineReducers())而不是创建多个store;
createStore:Redux中最核心的API。
其职责有:
getState()方法获取state;dispatch(action)方法更新state;subscribe(listener)注册监听器,这个方法在store发生变化时被调用;subscribe(listener)返回的函数注销监听器。// 通过createStore方法创建一个store
import { createStore } from 'redux';
const store = createStore(reducers);
异步流:由于Redux所有对store状态的变化,都应该通过action触发,异步任务也不例外,而为了不将业务或数据相关的任务混入React组件中,就需要使用其他框架配合管理异步任务流程,如redux-thunk、redux-saga等。
它有三大原则:
MobX是一个透明函数响应式编程的状态管理库。它的原则是:任何起源于应用状态的数据应该自动获取。
图5. MobX运作流程
State(状态):按领域划分状态,最后用RootStore来组合所有stores;
Derivations(衍生):源自状态且不会再有任何进一步的相互作用。又分为2种类型:
observable 可观察者,可以被观察者观察的数据;
observer 观察者,可以观察可观察者的对象,可以接收到可观察者发生变化时候发出的消息,并且根据变化做出响应;
observer本身是一个函数,也可以以装饰器的身份出现,将其包装过的对象变成一个观察者。
Actions(动作):是任何一段可以改变状态的代码,比如用户事件、后端数据推送等等。MobX并不强制使用Actions,你可以直接用DOM的onClick来触发修改Store,但是在严格模式(enforceActions)下MobX强制只有在动作中才可以修改状态。
MobX秉承了Flux的单向数据流**,即动作改变状态、状态的改变令所有受影响的视图更新。
当状态变化时,所有衍生都会进行自动更新(类似Vue.js的computed),因此永远不能观察到中间值。
Redux vs MobX:

图6. Vuex运作流程
Flux架构模式为我们提供了一种解决复杂项目状态管理的思路,对它进行实现的库有很多,本文分析了3个:Redux、MobX、Vuex。
MobX更容易上手,但其较松散的限制可能比起Redux来,略微不适用于大型而复杂的项目。有人说MobX更加与框架无关、可以同时用在React和Vue项目中,其实现在的状态管理工具都是秉承单一功能原则、都能做到与框架无关。
Vuex在Vue项目中有天然优势,因为它是针对Vue特化的Flux、配合了Vue本身的响应式机制。MobX也是基于数据劫持和依赖收集的响应式的、并且MobX的设计也借鉴了Vue,当然它也能配合Vue的(mobx-vue,其中心**是用MobX的响应式机制接管Vue的Watcher,将Vue降级成一个纯粹的装载DOM的组件渲染引擎)。引用一段话:
Mobx + React组合提供的能力恰好是Vue与生俱来的。而mobx-vue做的事情则刚好相反:将Vue降级成React,然后再配合MobX升级成Vue。这确实很怪异,但我想说的是,我们的初衷并不是说Vue的响应式机制实现得不好从而用MobX替换掉,而是希望借助MobX这个相对中立的状态管理平台,面对不同视图层技术提供一种相对通用的数据层编程范式,从而尽量抹平不同框架间的语法及技术栈差异,以便为开发者提供更多的视图技术的决策权及可能性,而不至于被某一框架绑架裹挟。
具体如何选择,你喜欢就好。
SemVer(Semantic Versioning,语义化版本控制)是Github起草的一个语义化版本号管理模块,它实现了版本号的解析和比较,规范版本号的格式。它解决了依赖地狱的问题。
语义化版本控制,顾名思义,就是让版本号更具有语义,可以传达出关于软件本身的一些重要信息而不只是简单的一串数字。
版本格式:主版本号.次版本号.修订号。
每个部分都为整数(>=0),按照递增的规则改变。
版本号递增规则:
先行版本号及版本编译信息可以加到“主版本号.次版本号.修订号”的后面,作为延伸:
判断优先层级时,必须把版本依序拆分为主版本号、次版本号、修订号及先行版本号后进行比较。由左到右依次比较每个标识符号,第一个差异值用来决定优先层级(其中字母连接号以ASCII排序进行比较、其他都相同时栏位多的先行版本号优先级较高)。如:1.0.0-alpha < 1.0.0-alpha.1 < 1.0.0-alpha.beta < 1.0.0-beta < 1.0.0 < 2.0.0 < 2.1.0 < 2.1.1。
<、<=、>、>=、=:指定版本范围,甚至可以通过||组合多个比较器。比如:
-:连字符表示版本号范围,表示的是一个闭区间。比如:
x、X、*:可以替代[主版本号.次版本号.修订号]三段中任意一段,表示该位置版本号没有限制;另外缺省三段中任意一段与用x、X或*替换该段效果相同。比如:
~:允许小版本迭代,具体规则:
例子:
^:允许大版本迭代,具体规则:
例子:
我们工程里package.json文件定义的包的版本是版本范围,比如:
"autoprefixer": "^7.1.2"执行npm outdated可以看到所有依赖的包的版本情况,其中autoprefixer:
执行npm view autoprefixer显示该包版本信息:
因为^7.1.2表示>=7.1.2 <8.0.0,而满足这个范围的版本中最高版本是7.2.6,所以Wanted为7.2.6。现在Current是7.2.5,即当前环境autoprefixer的版本是7.2.5,在测试环境构建时它可能是7.2.6,这就导致了测试环境和开发环境包版本不一致,可能会引发问题。
所以我们需要锁定版本号以保证测试环境(线上环境)和开发环境包版本保持一致、以提高代码稳定性。
给定版本,而不是使用版本范围。
"autoprefixer": "7.1.2"缺点:对于一个值得信赖的模块(严格遵循semver原则),开发者通过^来锁定一个模块的大版本,这样在每次重新安装依赖或打包的时候,都能够享受到这个包所有的新增功能和bug修复。现在舍弃了^或~,就只能手动升级包了。
shrinkwrap
可以通过执行npm shrinkwrap生成npm-shrinkwrap.json文件来手动锁定版本(按照当前项目node_modules目录内的安装包情况生成稳定的版本号描述)。当执行npm i时,npm会检查在根目录下有没有npm-shrinkwrap.json文件,如果有,npm会使用它(而不是package.json)来确定安装的各个包的版本号信息。
package-lock.json。
Default lockfiles
Shrinkwrap has been a part of npm for a long time, but npm@5 makes lockfiles the default, so all npm installs are now reproducible. The files you get when you install a given version of a package will be the same, every time you install it.
We’ve found countless common and time consuming problems can be tied to the “drift” that occurs when different developer environments utilize different package versions. With default lockfiles, this is no longer a problem. You won’t lose time trying to figure out a bug only to learn that it came from people running different versions of a library.
npm 5以上版本新增默认的lock文件。lock文件是整个npm包依赖关系树的快照,包含了所有包及其解析的版本,允许在不同机器间的重复构建。
相比于shrinkwrap,后者可以实现同样的效果,但package-lock.json表示npm真正支持了locking机制。另外,npm强制package-lock.json不会被发布。
npm会在安装包时自动创建 package-lock.json(除非已经有 npm-shrinkwrap.json),并在必要时更新它。
运行已经带有 package-lock.json 文件的 npm shrinkwrap 命令将只会对其重命名为 npm-shrinkwrap.json。
当两个文件处于某些原因同时存在时,package-lock.json 将被忽略。
注意:工作中遇到了一个问题,用了package-lock之后测试环境与本地安装的包不同,这是因为测试环境npm版本是3.#.#,根本不支持package-lock的。
yarn.lock
yarn默认提供lock功能(在安装依赖之后,生成一个锁文件[lockfile]来保存你的依赖树中每个模块的精确版本),也就是说,在通过yarn安装了一次依赖后,如果不执行 yarn upgrade,删除后再重新安装的模块的版本不会发生变化、每次发布应用也都将下载完全相同的包代码。
优点:
在所依赖的包都严格遵循semver时,使用^、~等范围规则是个不错的选择,然而事实是,总有不遵守规则的。这时候为了提高代码稳定性,锁定版本号就十分有必要了。至于使用什么方式来锁定版本,npm package-lock.json 还是 yarn.lock,那就见仁见智了。
2018年07月23日
现有两个文件:
// test1.json
{
"a": "a1",
"b": "b1"
}// test2.js
module.exports = {
obj: {
'b': 'b2',
'c': 'c2'
}
}如何把test2.js的obj合并(merge)到test1.json里呢?
基本思路:
利用Object.assign()把test1.json的对象和test2.js的obj对象进行merge,把merge后的对象写入test1.json
实现:
const fs = require('fs')
const path = require('path')
let targetPath1 = path.join(__dirname, './test1.json')
let targetPath2 = path.join(__dirname, './test2.js')
// 读取test1.json,将读取的字符串转换成JSON对象
let targetPath1Content = JSON.parse(fs.readFileSync(targetPath1))
// 获得test2.js的obj对象
let targetPath2Content = require(targetPath2).obj
// 合并(merge)两个对象
Object.assign(targetPath1Content, targetPath2Content)
// 将合并的对象转换成格式化后的JSON字符串(使用4个空格缩进),写入test1.json
fs.writeFile(targetPath1, JSON.stringify(targetPath1Content, null, 4), (error) => {
if (error) {
console.log('test error:', error)
return
}
console.log('test success')
})结果:
对JSON.stringify()的参数进行额外说明:
JSON.stringify(value[, replacer[, space]])2018年09月25日
看到Decorator(修饰器/装饰器)自然而然就会想到面向对象程序设计(OOP)的设计模式之一装饰器模式(Decorator Pattern)。OOP的装饰器模式允许向一个现有的对象添加新的功能(行为)、同时又不改变其结构。
ES7的Decorator依赖ES5的Object.defineProperty方法,它其实是一个语法糖:
function readonly(target, key, descriptor) {
descriptor.writable = false
return descriptor
}
class Dog {
@readonly
bark () {
return 'wang!wang!'
}
}
let dog = new Dog()
dog.bark = 'miao!miao!'
dog.bark() // "wang!wang!"用Babel官网提供的在线转码器(注意添加插件:babel-plugin-transform-decorators-legacy)进行转码:
var _desc, _value, _class;
function _applyDecoratedDescriptor(target, property, decorators, descriptor, context) {
var desc = {};
Object['ke' + 'ys'](descriptor).forEach(function (key) {
desc[key] = descriptor[key];
});
desc.enumerable = !!desc.enumerable;
desc.configurable = !!desc.configurable;
if ('value' in desc || desc.initializer) {
desc.writable = true;
}
desc = decorators.slice().reverse().reduce(function (desc, decorator) {
return decorator(target, property, desc) || desc;
}, desc);
if (context && desc.initializer !== void 0) {
desc.value = desc.initializer ? desc.initializer.call(context) : void 0;
desc.initializer = undefined;
}
if (desc.initializer === void 0) {
Object['define' + 'Property'](target, property, desc);
desc = null;
}
return desc;
}
function readonly(target, key, descriptor) {
descriptor.writable = false;
return descriptor;
}
let Dog = (_class = class Dog {
bark() {
return 'wang!wang!';
}
}, (_applyDecoratedDescriptor(_class.prototype, 'bark', [readonly], Object.getOwnPropertyDescriptor(_class.prototype, 'bark'), _class.prototype)), _class);
let dog = new Dog();
dog.bark = 'miao!miao!';_applyDecoratedDescriptor方法中 return decorator(target, property, desc) || desc; 把target、property、descriptor等参数传给readonly装饰器函数;readonly函数改写writable属性、返回新的descriptor;最后把这个新返回的descriptor应用到目标方法上。
上面的例子是将Decorator作用在方法/属性上,它还可以作用在类上。
function doge (target) {
target.isDoge = true
}
@doge
class Dog {}
console.log(Dog.isDoge) // true可以看到作用在类上的Decorator接收的第一个参数target是类本身,它修改了Dog这个类的行为、为它加上了静态属性isDoge。
作用在方法/属性上的Decorator接收的第一个参数target是类的prototype。
function dec (id) {
console.log('enter', id)
return (target, property, descriptor) => {
console.log('exec', id)
}
}
class Example {
@dec(1)
@dec(2)
test () {}
}
// enter 1
// enter 2
// exec 2
// exec 1core-decorators.js是一个第三方模块,封装了一些修饰器,比如@OverRide, @deprecate, @autoBind, @mixin等等。
在实践中如何使用Decorator,可以参考这篇文章, 它用一个生动的例子介绍了Decorator的用法。
2019年04月16日23:51:13
从VB、C++、C、Delphi 到 Java,2007年到2014年间一直接触的是面向过程编程语言(结构化程序设计语言)和面向对象编程语言,以至于正式入门JavaScript时对它的别扭的伪造的面向对象感到非常迷惑。
今天就来盘一盘它,彻底弄清楚把我弄晕的这几个词:__proto__、prototype、[[prototype]]、constructor。
object的英文解释是:
A thing that you can see or touch but that is not usually a living animal, plant, or person.
翻译下就是:object是指可看见或可触摸的实物(非活物)。
在程序界,万物皆是object。
对象应该是下列事物之一:
- 一个可以触摸或者可以看见的东西;
- 人的智力可以理解的东西;
- 可以指导思考或行动(进行想象或施加动作)的东西。
对象有如下几个特征:
- 对象具有唯一标识性:即使完全相同的两个对象,也并非同一个对象;
- 对象有状态:同一对象可能处于不同状态之下;
- 对象具有行为:即对象的状态,可能因为它的行为产生变迁。
C++、Java选择了用"类"来描述对象(基于类);而JavaScript选择用"原型"(基于原型)。
看下面一段代码:
var o = { a: 1 };
var p = { a: 1 };
console.log(o1 == o2); // false
var q = {
a: 1,
f(){
console.log(this.a);
}
}
上面代码中,o和p进行等值比较、结果是false,满足了对象的第一个特征:对象具有唯一标识性;q有状态(a:1),有行为(函数f),满足了对象的第2、3个特征。所以显然,JavaScript是面向对象的语言。
在不同的编程语言中,设计者利用各种不同的语言特性来抽象描述对象。
最为成功的流派是使用"类"的方式。
"基于类"的编程提倡使用一个关注分类和类之间关系的开发模型。
"基于原型"的编程看起来更为提倡关注一系列对象实例的行为,而后才去关心如何将这些对象,划分到最近的使用方式相似的原型对象,而不是将它们分成类。
基于原型的面向对象系统通过"复制"的方式来创建新对象。
原型系统的"复制操作"采用这样的思路:并不真的去复制一个原型对象,而是使得原型对象持有一个原型的引用。
那么JavaScript的原型系统究竟是怎样的呢?
那么问题来了,考虑下面的代码:
Function instanceof Object; // true
Object instanceof Function; // true这又是怎么回事?
实际上:
Function.__proto__.__proto__ === Object.prototype; // true
Object.__proto__ === Function.prototype; // true难道是鸡生蛋的问题?
按照上面打印的结果进行画像:
继续探索:
var obj = {
a: 1
}
var Parent = function () {
this.a = 2;
}
Parent.prototype.test = function () {
console.log(this.a)
}
var child = new Parent;对上面输出进行画像:
观察上图,发现仍然有一些疑点:
针对上面问题,我们再来探索下:
class Parent{
constructor() {
this.a = 1;
}
test1 () {
console.log(this.a)
}
}
class Child extends Parent{
constructor() {
super();
this.a = 2;
}
test2 () {
console.log(this.a)
}
}
var parent = new Parent();
var child = new Child();可以看出,
很显然,对于上面第3个问题,String等构造函数分别有各自的模板对象,且它们的模板对象不是模板对象1或模板对象2。而String等构造函数的模板对象的原型,是模板对象1。
至此,我们可以画出一个较完整的原型关系:
对上述的鸡生蛋的问题可以尝试解释下:
Function.__proto__.__proto__ === Object.prototype; // true
Object.__proto__ === Function.prototype; // trueFunction是一个创造构造函数的机器,包括创造Function这个构造函数,也包括作为构造函数的Object:
var s = new String();
s.__proto__ === String.prototype; // true
var o = new Object();
o.__proto__ === Object.prototype; // true
Function.prototype === Function.__proto__; // true【同样的,还有自己生自己:Function.__proto__ === Function.prototype,Object.__proto__.__proto__ === Object.prototype】
每个对象都有一个__proto__属性,指向它的原型;函数有prototype属性,指向它的模板对象;__proto__和prototype将JavaScript中的函数和对象连接起来,形成原型系统。
__proto__属性是一个访问器属性(一个getter函数和一个setter函数),暴露了通过它访问的对象的内部[[prototype]](一个对象或null)。
constructor返回创建实例对象的构造函数的引用。此属性的值是对函数本身的引用,而不是一个包含函数名称的字符串。所有对象都会从它的原型上继承一个constructor属性。
从ES5开始,所有属性都具备了属性描述符(也可称为数据描述符,因为它只保存一个数据值)。
从一个例子讲起:
var myObject = {};
Object.defineProperty( myObject, 'a', {
value: 2,
writable: true,
configurable: true,
enumerable: true
} );
myObject.a; // 2
我们使用Object.defineProperty()给myObject添加了一个普通的属性a,并显示指定了一些特性:
var myObject = {};
Object.defineProperty( myObject, 'a', {
value: 2,
writable: false, // 不可写
configurable: true,
enumerable: true
} );
myObject.a = 3;
myObject; // 2
var myObject = {
a: 2
};
myObject.a = 3;
myObject.a; // 3
Object.defineProperty( myObject, 'a', {
value: 4,
writable: true,
configurable: false, // 不可配置
enumerable: true
} );
myObject.a; // 4
myObject.a = 5;
myObject.a; // 5
Object.defineProperty( myObject, 'a', {
value: 6,
writable: true,
configurable: true, // 试图重新设置为可配置
enumerable: true
} ); // TypeError
接着我们来看一个例子:
var a = 0;
var myObject = {
a: 1
};
b; // ReferenceError
myObject.b; // undefined
同样都是不存在的,访问不存在的变量会抛出ReferenceError,访问不存在的对象属性则返回undefined,这是因为对对象属性的访问其实是通过对象内置的[[Get]]操作(有点像函数调用:[[Get]] ( ))来进行的。
对象默认的内置[[Get]]操作首先在对象中查找是否有同名属性,没找到就去原型链([[Prototype]]链)上查找,没找到就会返回undefined(内部是很复杂的算法)。
有获取属性值的[[Get]]操作,也就有对应的[[Put]]操作。
[[Put]]被触发时,如果目标对象中已经存在这个属性,[[Put]]算法会检查下面这些内容:
1. 属性是否是访问描述符?如果是并且存在setter就调用setter;
2. 属性的数据描述符中writable是否为false?如果是,在非严格模式下静默失败,在严格模式下抛出TypeError异常;
3. 如果都不是,将该值设置为属性的值。
如果对象中不存在这个属性,则会遍历[[Prototype]]链:
1. 如果原型链上找不到该属性,该属性就会被添加到目标对象上;
2. 如果该属性既出现在目标对象上、也出现在其原型链上层,那么目标对象上的该属性会屏蔽原型链上层的所有同名属性;
3.如果该属性只存在于原型链上层,则有三种情况:
3.1. 如果该属性是普通数据访问属性并且没有被标记为只读(writable:false),那就会直接在目标对象中添加一个新属性,他屏蔽原型链上层所有同名属性;
3.2. 如果该属性被标记为只读,那么无法修改已有属性或者在目标对象上创建屏蔽属性。在严格模式下会报错;在非严格模式下会静默失败;
3.3. 如果该属性是个setter,那就一定会调用这个setter,该属性不会被添加到目标对象上,也不会重新定义该属性这个setter。
对象默认的[[Get]]操作和[[Put]]操作分别可以控制属性值的获取和设置,在ES5中可以使用getter和setter部分改写默认操作,但是只能应用在单个属性上(无法应用在整个对象上)。getter、setter是隐藏属性,getter会在获取属性值时调用,setter会在设置属性值时调用。
当你给一个属性定义getter、setter或者两者都有时,这个属性会被定义为“访问描述符”。对于访问描述符来说,JavaScript会忽略他们的value和writable特性,取而代之的是关心的set和get(还要configurable和enumerable)特性。
var myObject = {
// 给a定义一个getter
get a() {
return 2;
}
};
Object.defineProperty(myObject, 'b', {
// 给b设置一个getter
get: function(){ return this.a * 2; }
});
myObject.a; // 2
myObject.b; // 4
不管是对象文法语法中的get,还是defineProperty中的显示定义,二者都会在对象中创建一个不包含值得属性(a、b)。对这个属性的访问会自动调用一个隐藏函数(所以叫访问描述符),它的返回值会被当做属性访问的返回值。
引申——不变性
在ES5中可以通过很多方法来实现令属性或对象不可改变。需要注意的是,所有这些方法创建的都是浅不变性,也就是说,它们只会影响目标对象和它的直接属性,如果目标对象引用了其他对象(数组、对象、函数等),其他对象的内容不受影响、仍然是可变的(只是令引用对象的地址变为不可变了)。
不变性从弱到强可以4种方法:
var myObject = {
a:2
};
Object.preventExtensions( myObject );
myObject.b = 3;
myObject.b; // undefined
参考资料:
需求:只展示某个登录用户有权限的导航菜单。
基本思路:获取到登录用户可访问的导航数据 → 生成提供给导航组件sideNav.vue的数据 → 处理没有权限的访问路径、令其跳转到403页面。
跟后端约定好的登录返回数据:
// login.json
{
"code": 0, // code >= 0 表示成功
"msg": "success",
"body": {
"data": {
"id": null,
"name": null,
"isDisplay": true,
"operateList": [{
"value": null
}],
"childsList": [{ // 一级菜单
"id": "2",
"parentId": null,
"name": "内容管理",
"operateList": [{
"value": null
}],
"childsList": [{ // 二级菜单
"id": "21",
"parentId": "2",
"name": "内容搜索",
"operateList": [{
"value": "/content/general/search" // 叶子菜单对应的跳转url
}]
}]
}]
}
}
}
步骤一,获取用户权限数据:
// App.vue
<script>
import api from 'api'
export default {
name: 'App',
methods: {
getRouter () {
api.getUserInfoAndMenu().then(res => {
let menu = res.data || {} // 用户权限数据
})
}
},
created () {
this.getRouter()
}
}
</script>
步骤二,处理获得的用户权限数据,生成菜单数据:
// App.vue
// ...
getRouter () {
api.getUserInfoAndMenu().then(res => {
let menu = res.data || {}
let actualMenu = menu.childsList || []
let sideMenus = this.productRouterAndMenu(actualMenu)
})
},
productMenu (menu) {
if (Array.isArray(menu)) {
let menuItem = menu.map(item => {
let url = item.operateList[0].value
return {
name: item.name || '',
url: url || '',
subMenus: this.productRouterAndMenu(item.childsList)
}
})
return menuItem
}
}
得到了菜单数据:
sideMenus: [{
'name': '生产者管理',
'url': '',
'subMenus': [{
'name': '权限管理',
'url': '/content/admin/authority',
'subMenus': undefined
}]
}, {
'name': '内容管理',
'url': '',
'subMenus': [{
'name': '内容搜索',
'url': '/content/general/search',
'subMenus': undefined
}]
}]
步骤三,把得到的菜单数据存到store实例的state中:
// App.vue
// ...
getRouter () {
api.getUserInfoAndMenu().then(res => {
let menu = res.data || {}
let actualMenu = menu.childsList || []
let sideMenus = this.productRouterAndMenu(actualMenu)
// 更新菜单
this.$store.dispatch('getSideMenus', sideMenus)
})
}
// store/actions.js
export const getSideMenus = ({ commit }, sideMenus) => {
commit(types.SIDE_MENUS, sideMenus)
}
export default {
// ...
getSideMenus
}
// store/mutation-types.js
export default {
// ...
SIDE_MENUS: 'SIDE_MENUS'
}
// store/mutations.js
export default {
// ...
[types.SIDE_MENUS] (state, sideMenus = []) {
state.sideMenus = sideMenus
}
}
// store/state.js
export default {
// ...
sideMenus: []
}
至此,导航组件 sideNav.vue 就可以拿到菜单数据 sideMenus 了。
到这里,我们的页面已经渲染除了需要呈现的菜单,现在配置下路由信息:
// router/fullRouter.js
// 完整的路由配置
import Page from '@/pages/page'
import Dashboard from '@/pages/dashboard'
import Error404 from '@/pages/error/404'
import Error403 from '@/pages/error/403'
import AuthorityManagement from '@/pages/admin/authorityManagement/authorityManagement'
import ContentSearch from '@/pages/general/contentSearch/contentSearch'
let fullRouter = [{
path: '',
name: 'home',
component: Page,
children: [{
path: '/content/admin',
name: '生产者管理',
redirect: '/content/admin/authority',
component: Dashboard,
children: [{
path: '/content/admin/authority',
name: '权限管理',
component: AuthorityManagement
}]
}, {
path: '/content/general',
name: '内容管理',
redirect: '/content/general/search',
component: Dashboard,
children: [{
path: '/content/general/search',
name: '内容搜索',
component: ContentSearch
}]
}]
}, {
path: '/403',
name: '403',
component: Error403
}, {
path: '*',
name: '404',
component: Error404
}]
export default fullRouter
// router/index.js
// ...
import FullRouter from './fullRouter'
let router = new Router({
mode: 'history',
routes: FullRouter
})
export default router
现在在地址栏手动输入/content/admin/authority,发现可以打开权限管理页面,而返回的用户权限数据没有这个权限,所以我们需要对导航做个导航守卫处理。
步骤四,添加导航守卫:
// App.vue
export default {
name: 'App',
data () {
return {
routersStr: '/404,/403', // 拼接所有有权限访问的连接
}
},
methods: {
getRouter () {
let self = this
api.getUserInfoAndMenu().then(res => {
// ...
// 全局导航守卫
this.routerGuard()
})
},
productRouterAndMenu (menu) {
if (Array.isArray(menu)) {
let menuItem = menu.map(item => {
let url = item.operateList[0].value
if (url) {
// 拼接所有有权限访问的连接
this.routersStr += ',' + url
}
return {
name: item.name || '',
url: url || '',
subMenus: this.productRouterAndMenu(item.childsList)
}
})
return menuItem
}
},
routerGuard () {
let self = this
this.$router.beforeEach((to, from, next) => {
// 如果是有权限访问的地址,则跳转;否则跳转到403页面
if (self.routersStr.includes(to.path)) {
next()
} else {
next({ path: '/403'})
}
})
}
},
created () {
this.getRouter()
}
}
刷新页面、在地址栏手动输入新路由,发现导航守卫没起作用。这是因为手动输入路由回车后,页面重新加载,路由挂载后(此时导航守卫还没挂载)才执行到App.vue里的导航守卫代码,所以导航守卫失效了。
步骤五,那么改用动态添加路由:
// ...
// 全局导航守卫
this.routerGuard()
// 动态添加路由
this.$router.addRoutes(FullRouter)
访问/content/admin/authority(没权限),成功跳转到403页面,看上去我们成功了。但是点击后退键,会再次返回到403页面,再点击一次后退键,才返回到上一个有权限访问的页面。
从现象来看,是没权限页面和403页面都被记录在浏览器历史里了,那么将next方法改为:next({ path: '/403', replace: true }), 再次访问/content/admin/authority(没权限)、在403页面点击后退键,成功返回上一个有权限访问的页面。
参考:
2019年01月09日
在LeetCode上刷到不少动态规划(Dynamic programming,简称DP)的问题,有一部分问题不能一下子想到解题思路,于是决定总结下动态规划算法,以后碰到此类问题可以快速解决。
wiki上对动态规划的介绍:
通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
看到这个介绍,我有两个疑惑:
在此简要阐述下这两篇文章的观点:
首先,我们需要了解下两个概念:状态和阶段。
一个问题的每个阶段的最优状态可以从之前某个阶段的某个或某些状态直接得到(这个性质叫做最优子结构)、而不管之前这个状态是如何得到的(这个性质叫做无后效性),那么这个问题就可以用动态规划来解决。
【补充解释下,所谓无后效性,指状态间的转移与如何到达某状态无关。如果有关,意味着你的状态描述不能完整而唯一地包括每一个状态。】
结合看下wiki上对动态规划的使用情况的介绍:
- 最优子结构性质。如果问题的最优解包含的子问题的解也是最优的,我们就称该问题具有最优子结构性质(即满足最优化原理)。
- 无后效应。即子问题的解一旦确定,就不再改变,不受在这之后、包含它的更大的问题的求解决策影响。
- 子问题重叠性质。子问题重叠性质是指在用递归算法自顶向下对问题进行求解时,每次产生的子问题并不总是新问题,有些子问题会被重复计算多次。动态规划算法正是利用了这种子问题的重叠性质,对每个子问题只计算一次,然后将其计算结果保存在一个表格中,当再次需要计算已经计算过的子问题时,只是在表格中简单地查看一下结果,从而获得较高的效率。
如何拆分问题,才是动态规划的核心。而拆分问题,靠的就是状态的定义和状态转移方程的定义。
用一个经典的例子——最长上升子序列(Longest Increasing Subsequence, LIS)问题举例说明下上述内容:
一个数的序列bi,当b1 < b2 < … < bN的时候,我们称这个序列是上升的。对于给定的一个序列(a1, a2, …, aN),我们可以得到一些上升的子序列(ai1, ai2, …, aiK),这里1 <= i1 < i2 < … < iK <= N。
比如,对于序列(1, 7, 3, 5, 9, 4, 8),它有一些上升子序列,如(1, 7),(3, 4, 8)等等。这些子序列中最长的长度是4,比如子序列(1, 3, 5, 8)。
我们的问题就是,对于给定的序列,其长度为N,求出最长上升子序列的长度。
状态定义。我们可以把这个问题重新描述为:
给定序列(a1, a2, …, aN),长度为N,
设Fi为 以数列中第i项结尾的最长递归子序列的长度,求F1、F2、…FN中的最大值。
对于Fi而言,F1…Fi-1都是Fi的子问题:因为以第i项结尾的LIS,包含以第1…i-1中某项结尾的LIS。
“设Fi为 以数列中第i项结尾的最长递归子序列的长度”即为对状态的定义(状态的定义不唯一)
状态转移方程。用来描述状态和状态之间的关系式。对求LIS长度问题,状态转移方程为:
Fi = max{Fj + 1}, 0<=j<i and aj<ai
从状态转移方程中可以看到,LIS问题满足:
所以,LIS问题可以用动态规划来解决。
结合上述介绍,总结动态规划解题步骤:
接下来用例子来实践一下动态规划算法。
给定一个序列,其长度为N,求出最长上升子序列的长度。
/**
* @param {Array} seq
* @return {Number}
*/
function LIS (seq) {
if (seq.length<=0) {
return 0;
}
let len = seq.length;
let meno = [1];
let result = 1;
for (let i=1; i<len; i++) {
meno[i] = 1;
for (let j=0; j<i; j++) {
if (seq[i] > seq[j]) {
meno[i] = Math.max(meno[i], meno[j]+1);
}
}
result = Math.max(result, meno[i]);
}
return result;
}你是一个职业抢劫犯,计划入室抢劫一条街的房子,每户人家都有一定数额的现金。相邻的两户人家之间连接有安全系统,如果相邻两户人家在同一个晚上被闯入,安全系统就会自动报警。
给定一个非负整数列表,表示每所房子里的现金数目,确定你今晚可以安全(没有触发报警系统)抢劫的最大钱数。
例子:
输入:[2,7,9,3,1]
输出:12
解释:抢劫房子1 (钱数 = 2),抢劫房子3 (钱数 = 9) ,抢劫房子5 (钱数 = 1)。合计可以抢劫的钱数 = 2 + 9 + 1 = 12。
/**
* @param {Array} nums
* @return {Number}
*/
function rob (nums) {
if (nums.length<=0) {
return 0;
}
let len = nums.length;
let meno = [0, nums[0]]
for(let i=1; i<len; i++) {
meno[i+1] = Math.max(meno[i], meno[i-1]+nums[i]);
}
return meno[len]
}/**
* @param {Array} nums
* @return {Number}
*/
function rob (nums) {
if (nums.length<=0) {
return 0;
}
let prev1 = 0;
let prev2 = 0;
for(let num of nums) {
let temp = prev1;
prev1 = Math.max(prev1, prev2+num);
prev2 = temp;
}
return prev1;
}2019年03月16日
稳定性:如果待排序的序列中存在值相等的元素,经过排序后,相等元素之间原有的先后顺序不变,我们就说这种排序算法是稳定的排序算法。
原地排序:是针对空间复杂度引入的一个概念,它特指指空间复杂度为O(1)的排序算法。
为了下面时间复杂度分析方便,我们先介绍下"有序度"和"逆序度"。
有序度是数组中具有有序关系的元素对的个数,逆序度是数组中具有逆序关系的元素对的个数:
有序元素对:a[i] <= a[j] ,如果 i<j
逆序元素对:a[i] > a[j],如果i<j
比如[2,4,3,1,5,6]这组数组,其有序元素对有:
(2,4)、(2,3)、(2,5)、(2,6)、(4,5)、(4,6)、(3,5)、(3,6)、(1,5)、(1,6)、(5,6) 共11个,所以其有序度为11;
其逆序元素对有:
(2,1)、(4,3)、(4,1)、(3,1) 共4个,所以其逆序度为4。
比如[6,5,4,3,2,1]的有序度是0;
而对于[1,2,3,…,n]这样完全有序的数组,其有序度就是
$$
C_n^2 = \frac{n(n-1)}{2}
$$
我们把这种完全有序的数组有序度叫做满有序度。
比如[1,2,3,4,5,6]的满有序度为15。
有序度 + 逆序度 = 满有序度。我们排序的过程就是一种增加有序度、减少逆序度的过程,最后达到满有序度、就说明排序完成了。
对数组进行交换以使其逐渐有序,假设每交换一次有序度就加1,那么不管算法如何改进、交换次数总是确定的,即为逆序数。
下面的排序算法都实现升序排序。
优化:当某次冒泡已经没有数据交换了,说明已经达到有序了,也就可以不再执行后续冒泡。
代码:
// 冒泡排序
function bubbleSort (array) {
if (!array || array.length <= 1) {
return;
}
let len = array.length;
for (let i=0; i<len; i++) {
let flag = false; // 本轮冒泡是否有数据交换
for (let j=0; j<len-i-1; j++) {
if (array[j]>array[j+1]) {
let temp = array[j+1];
array[j+1] = array[j];
array[j] = temp;
flag = true;
}
}
if (!flag) {
break; // 本轮冒泡没有数据交换,提前退出
}
}
}由代码可以看出:
插入排序顾名思义,通过将元素插入数组中它该在的位置来进行排序。
代码:
// 插入排序
function insertSort (array) {
if (!array || array.length <= 1) {
return;
}
let len = array.length;
// 遍历未排序区
for (let i = 1; i<len; i++) {
let val = array[i];
let j = i-1;
// 在已排序区查找插入位置
for (; j>=0; j--) {
if (array[j] > val) { // 比较
array[j+1] = array[j]; // 移动
} else {
break;
}
}
array[j+1] = val; // 找到插入位置、插入[1.已排序区未遍历完找到插入位置,break;出来插入;2.以排序区已遍历完、已排序区所有元素右移一位、所以在遍历结束后插入到已排序前第1位]
}
}由代码可以看出:
另外,冒泡排序和插入排序不管怎么优化,它们的元素交换/移动(插入排序的移动也是增加有序度的过程)次数是固定的、为逆序度,但是从代码上看,冒泡排序的数据交换要比插入排序的数据移动复杂,冒泡需要3个赋值操作,而插入只需1个移动操作:
// 冒泡排序中数据的交换操作
if (array[j]>array[j+1]) {
let temp = array[j+1];
array[j+1] = array[j];
array[j] = temp;
flag = true;
}
// 插入排序中数据的移动操作
if (array[j] > val) { // 比较
array[j+1] = array[j]; // 移动
} else {
break;
}所以虽然都是O(n^2)时间复杂度,如果我们希望把性能优化做的极致,比起冒泡排序、肯定选插入排序(插入排序还有很大优化空间,比如希尔排序)。
插入排序每次都需要在已排序区遍历查找插入位置,如果我们只在已排序区末尾插入呢?那就是选择排序。(插入排序重点在插入;而选择排序,顾名思义,重点在选择。)
代码:
// 选择排序
function selectSort(array) {
if(!array || array.length<=1) {
return;
}
let len = array.length;
for(let i=0; i<len-1; i++) {
let min = i;
for (let j=i+1; j<len; j++) {
if (array[j] < array[min]) {
min = j; // 找到未排序区中的最小元素
}
}
// 将未排序区中的最小元素通过交换方式放入已排序区末尾
let temp = array[i];
array[i] = array[min];
array[min] = temp;
}
}由代码可以看出:
代码:
// 归并排序
function mergeSort(array) {
if (!array || array.length<=1) {
return;
}
sort(array, 0, array.length-1);
}
function sort (array, left, right) {
if (left > right) {
return;
}
let mid = Math.floor((left + right)/2);
merge(sort(array, left, mid), sort(array, mid+1, right))
}
function merge (array1, array2) {
let len1 = array1.length,
len2 = array2.length;
let result = new Array(len1+len2);
let i = j = 0;
while (i<=len1 && j<=len2) {
if (array1[i] <= array[j]) {
result.push(array1[i]);
i++;
} else {
result.push(array2[j]);
j++;
}
}
while (i<=len1) {
result.push(array1[i]);
i++;
}
while (j<=len2) {
result.push(array2[j]);
j++;
}
return result;
}由代码可以看出:
归并排序稳不稳定要看merge()函数,代码中当左右数组存在相同值时、先把左数组的值放入合并的数组,这样保证了稳定性,所以归并排序是一个稳定的排序算法;
归并排序时间复杂度 = 子问题时间复杂度 * 2 + 合并的时间复杂度
根据上面代码递推公式我们可以得到时间复杂度递推公式:
T1 = C; n=1时只需要常量级的执行时间
Tn = 2 * T(n/2) + n; n >1所以:
Tn = 2 * T(n/2) + n
= 2 * (2 * T(n/4) + n/2) + n = 4 * T(n/4) + 2n
= 2 * (2 * (2 * T(n/8) + n/4) + n/2) + n = 8 * T(n/8) + 3n
= ...
= 2^k * T(n/2^k) + k * n
= ...当T(n/2^k) = T(1)时 => n/2^k = 1 => 2^k = n => k = log2(n)。
根据递归终止条件:T1 = C,Tn = n * C + n * log2(n)。
所以用大O表示法,Tn就等于O(nlogn),即归并排序的时间复杂度是O(nlogn)。
我们从原理和代码可以看出,归并排序的执行效率与要排序的原始数组的有序程序无关,所以其最好、最坏、平均情况时间复杂度都是O(nlogn)。
但是归并排序有一个致命弱点,那就是它不是原地排序的,它的空间复杂度是O(n)。[尽管每次合并都需要申请额外空间,但是在合并操作结束后,临时开辟的控件就被释放掉了,所以临时空间最多也就是n。]
代码:
// 快速排序
function quickSort (array) {
if (!array || array.length<=1) {
return;
}
sort(array, 0, array.length-1);
}
function sort(array, left, right) {
// 区间缩小至区间内只有1个元素、则该区间已经排好序
if (left >= right) {
return;
}
let pivot = partition(array, left, right); // 获取分区点
sort(array, left, pivot-1);
sort(array, pivot+1, right)
}
function partition (array, left, right) {
// 为了实现原地排序算法,采用类似选择排序的 从“未处理区”取出小于pivot的元素插入到“已处理区”末尾,通过交换方式
// 这里选取最后一个元素为pivot
let pivot = array[right];
let i = left; // 标记”已处理区“尾部
for (let j=left; j<=right-1; j++) { // 注意:从left到right-1找小于pivot的元素、将其放到左边“已处理区”
if (array[j]<pivot) {
let temp = array[i];
array[i] = array[j];
array[j] = temp;
i++;
}
}
// 将pivot放到中间
let temp = array[i];
array[i] = array[right];
array[right] = temp;
// 返回分区点
return i;
}注意:上述代码中"已处理区"并不是真的如插入、选择排序一样的已排好序的区域,而是为了更好理解分区操作中跟选择排序类似的通过交换方式、从“未处理区”取出小于pivot的元素插入到“已处理区”末尾
由代码可以看出:
另外,
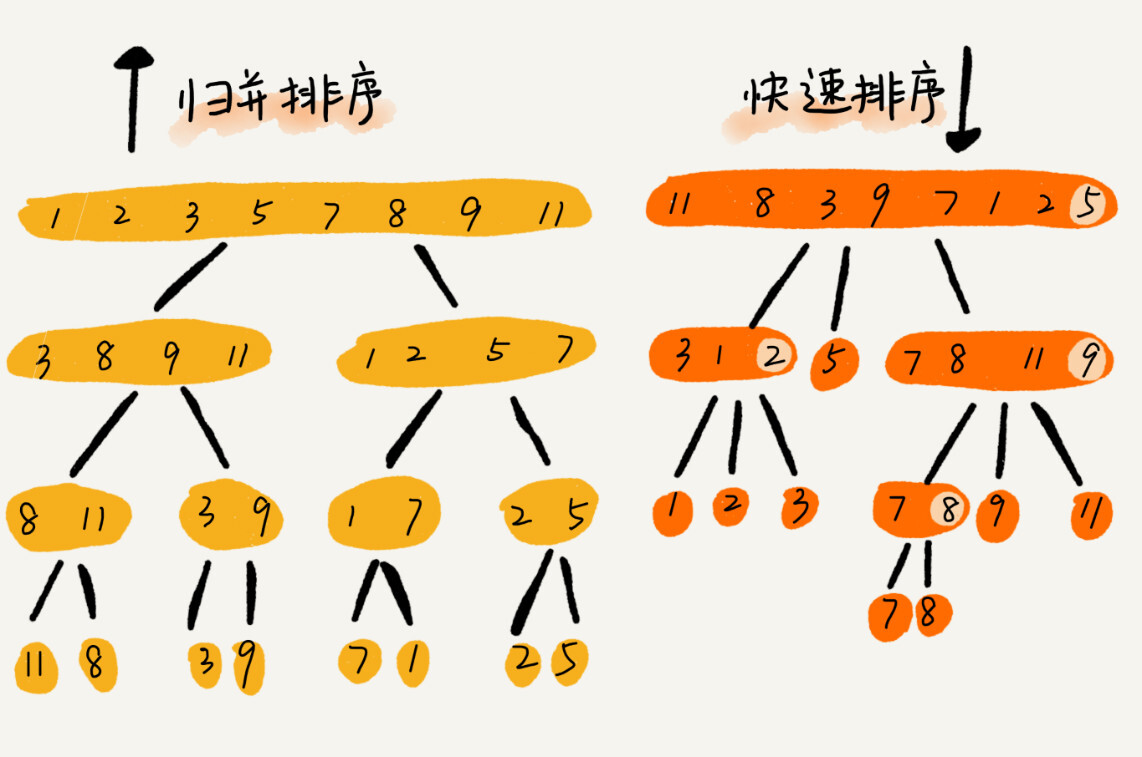
桶排序顾名思义,"桶"是用来排序的主角。
计数排序其实是桶排序的一种特殊情况。
| 排序算法 | 最好情况时间复杂度 | 最坏情况时间复杂度 | 平均情况时间复杂度 | 空间复杂度 | 是否原地排序 | 稳定性 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 是 | 稳定 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 是 | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 是 | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 否 | 稳定 |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) | 是 | 不稳定 |
| 桶排序 | O(n) | O(nlog)或O(n^2),取决于桶内排序算法 | O(n) | O(n+k)[?有疑问] | 否 | 稳定 |
| 计数排序 | O(n + k) | k是数据范围 | O(n + k) | O(n) | O(k) | 否 | 稳定 |
| 基数排序 | O(dn)|d是维度 | O(dn) | O(dn) | O(n + d)[?有疑问] | 否 | 稳定 |
另外经典排序还有希尔排序、堆排序等,下次有空再整理把。
组件之间的通信可以用下图表示:
由此图可知,组件通信可分为:父子组件通信、兄弟组件通信、跨级组件通信。
一.父子组件通信
父组件向子组件通信,通过props传递数据就可以了;子组件则通过$emit来向父组件抛出事件(父组件需要监听相应的事件)。
看下以下实例:
// parent.vue
<template>
<div class="parent">
<p>父亲:给你{{ money }}元零花钱</p>
<kid :money="money" @repay="repay"></kid>
<br>
<button @click="add">那给你加100</button>
<p v-if="back" @repay="repay">儿子:超过300我不要,还给你 {{ back }}元</p>
</div>
</template>
<script>
export default {
name: 'parent',
data () {
return {
money: 100,
back: 0
}
},
components: {kid},
methods: {
repay (back) {
this.back = back
},
add(){
this.money += 100;
}
}
}
</script>
// kid.vue
<template>
<div class="parent">
<p v-if="pocketMoney < 300">儿子: {{ pocketMoney }}太少了,不够 </p>
<p v-else>儿子: 谢谢老爸!</p>
<button v-if="pocketMoney > 300" @click="repay">点击有惊喜</button>
</div>
</template>
<script type="text/javascript">
export default {
name: 'kid',
props: {
money: Number
},
data () {
return {
}
},
computed: {
pocketMoney () {
return this.money;
}
},
methods: {
repay () {
this.$emit('repay',this.pocketMoney-300)
}
}
}
</script>
父亲给儿子零花钱,父亲通过props将钱给到儿子,儿子拿到钱后通过计算属性得到自己的零花钱;父亲觉得零花钱太少了,给儿子超过300块;儿子比较乖,只需要300,于是发送了一个自定义事件repay,将超过300块的钱还给父亲,父亲通过监听repay这个事件的回调拿到儿子还给他的钱。
二.非父子组件通信(兄弟组件通信、跨多级组件通信)
Vue.js 1.x中提供了两个方法$dispatch()和$broadcast()。$dispatch()用于向上级派发事件,只要是它的父级(一级或多级),都可以在Vue实例的events选项内接收;同理,$broadcast()是由上级向下级广播事件的,用法与$dispatch()完全一致,只是方向相反。这两种方法一旦发出事件后,任何组件都是可以接收到的,根据就近原则,会在第一次接收到后停止冒泡、除非返回true。
这两个方法虽然看起来很好用,但在Vue.js 2.x中被废弃了,因为基于组件树结构的事件流方式让人难以理解,并且在组件结构扩展的过程中会变得越来越脆弱,并且不能解决兄弟组件通信的问题。
在Vue.js 2.x中,推荐使用一个空的Vue实例作为**事件总线(bus),就跟房屋中介一样:租房者和出租者都会找中介登记,中介把匹配的租房者信息给出租者、把匹配的出租者的信息给租房者。整个过程中,租房者和出租者并没有任何角落,都是通过中介来传话的。另外,假如租房者打算换房,租房者找中介登记,并订阅跟租房者需求有关的资讯,一旦有符合需求的房子出现,中介就会通知你,并传达该房子的具体信息。
在这两个例子中,租房者和出租者担任的就是两个跨级(一级或多级)组件,而房产中介就是这个**事件总线(bus)。示例代码如下:
<div id="app">
{{ message }}
<renter></renter>
</div>
<script>
var bus = new Vue();
//出租者组件
Vue.component('renter', {
template: '<button @click="handleEvent">传递信息</button>',
methods: {
handleEvent: function () {
bus.$emit('on-message', '来自出租者的信息')
}
}
});
//租房者实例
var app = new Vue({
el: '#app',
data: {
message: ''
},
mounted: function () {
var that = this;
//在实例初始化时,监听来自bus实例的事件
bus.$on('on-message', function(msg){
that.message = msg;
});
}
});
</script>
这种方法巧妙而轻量地实现了任何组件间的通信,包括父子、兄弟、跨级。当我们的项目比较大时,可以选择更好的状态管理解决方案vuex。
除了bus外,还有两种方法可以实现组件间通信:父链和子组件索引。
父链
在子组件中,使用this.$parent可以直接访问该组件的父实例或组件,父组件也可以通过this.$children访问它所有的子组件,而且可以递归向上或向下无限访问,直到根实例或最内层的组件。尽管Vue允许这样操作,但在业务中子组件应该尽可能地避免依赖父组件的数据,更不应该去主动修改它的数据,因为这样使得父子组件紧耦合:只看父组件,很难理解父组件的状态,因为它可能被任意组件修改。理想情况下,只有组件自己能修改它的状态。父子组件最好还是通过props和$emit来通信。
子组件索引
当子组件较多时,通过this.$children来一一遍历出我们需要的一个组件实例是比较困难的,尤其是组件动态渲染时,它们的序列是不固定的。Vue提供了子组件索引的方法,用特殊的属性ref来为子组件指定一个索引名称。用法:在父组件模板中,子组件标签上使用ref指定一个名称,并在父组件内通过this.$refs来访问指定名称的子组件。
注意:$refs只在组件渲染完成之后才填充,并且它是非响应式的,它仅仅作为一个直接访问子组件的应急方案,应当避免在模板或计算属性中使用$refs。
总结,父子组件通信使用props和this.$emit;在父组件中访问子组件可以使用子组件索引;兄弟组件通信、跨级组件通信可以使用**事件总线(bus),复杂项目可以使用vuex。
参考资料:
1.Vue.js实战 梁灏
2.http://whutzkj.space/2017/08/05/vue%E7%BB%84%E4%BB%B6%E4%B9%8B%E9%97%B4%E7%9A%84%E9%80%9A%E4%BF%A1%EF%BC%88%E4%B8%80%EF%BC%89/#more
在Vue官方文档里,有这样一段内容:
由于JavaScript的限制,Vue不能检测以下变动的数组:
为了解决第一类问题,以下两种方式都可以实现和 vm.items[indexOfItem] = newValue 相同的效果,同时也能触发状态更新:
// Vue.set
Vue.set(example1.items, indexOfItem, newValue)
// Array.prototype.splice
example1.items.splice(indexOfItem, 1, newValue)
为了解决第二类问题,可以使用 splice:
example1.items.splice(newLength, 0, undefined)
其中Array.splice( )方法用于从一个数组中移除元素,如有必要,在所移除元素的位置上插入新元素,并返回所移除的元素,而原数组被改变。
其语法为:
arrayObject.splice(index, howmany, [item1[,item2[,…[,itemN]]]])
所以上面的第二个方法(Array.prototype.splice)在example1里添加了新值newValue,并改变了example1本身。【Vue重新封装了包括Array.prototype.splice在内的许多数组方法,这些方法会把数据属性转换为访问器属性】
对于对象,还可以用Object.assign( )浅拷贝一个对象来解决(替换掉vm.data的原对象):
vm.user = Object.assign({}, vm.user, {age: 18, name: ’zoro'})
那么为什么直接对数组(或对象)利用索引进行设值、直接更改length时不会触发状态更新呢?Vue官方文档只说“由于JavaScript的限制”,那么这个限制到底是什么呢?
Vue监听数据变动,是利用了JavaScript的Object.definedProperty方法,依靠descriptor里的getter和setter这两个访问器属性。(Vue不支持IE8以下浏览器就是因为IE8以下浏览器不支持Object.definedProperty)
new Vue(obj) 时(初始化实例时),其内部发生了大体如下的代码转换(将数据属性,转换为了访问器属性):
function Vue (obj) {
// 遍历对象所有的属性,并使用Object.defineProperty
// 把这些属性全部转为getter/setter
obj.data.keys().forEach((item, index) => {
Object.defineProperty(obj.data, item, {
set () {
// 可以在此处进行事件监听
},
get () {
//
}
})
})
return obj;
}
所以当使用索引给数组或对象添加属性(如 vm.items[0] = {})时,是直接 = 赋值,是数据属性的(而不是访问器属性),是默认的[[Get]]操作和[[Put]]操作,所以无法检测变动。
至于push等操作可以检测到变动,是因为Vue把这些Api重新封装了。
每个组件实例都有相应 watcher 实例对象,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的 setter 被调用时,会通知 watcher 重新计算,从而致使它关联的组件得以更新。
另外,Vue不允许在已经创建的实例上动态添加新的根级响应式属性,所以必须在初始化实例前声明根级响应式属性,哪怕只是一个空值:
var vm = new Vue({
data: {
// 声明 message 为一个空值字符串
message: ''
},
template: ‘<div>{{ message }}</div'
})
// 之后设置 `message`
vm.message = ‘Hello!'
这样的限制,除了消除了在依赖项跟踪系统中的一类边界情况,也使Vue实例在类型检查系统的帮助下运行得更高效。而且在代码可维护方面也有一点重要的考虑:data 对象就想组件状态的概要,提前声明所有的响应式属性,可以让代码在以后重新阅读或其他开发人员阅读时更易于被理解。
Vue不允许在已经创建的实例上动态添加新的根级响应式属性,即只有 data 中的数据才是响应式的、动态添加进来的数据默认是非响应式的,但是对data里已经声明的属性(该属性为数组或对象)的响应式子属性可以使用特定的方法动态添加:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.