Good OCR, for game hacking captchas and other automation.
For very ood quality input images, it outperformed both tesseract and google cloud vision ( when it was made )
Example Image:
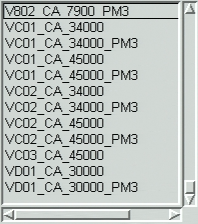
Extracted Text Output:
ver:ver2
FileType:CharactersMerged
TEXT:5,208,15,10,0.000000,V802 CA 7900 PM3
TEXT:5,192,9,10,0.000000,VC01_CA_34000
TEXT:5,176,9,10,0.000000,VC01_CA_34000_PM3
TEXT:5,160,9,10,0.000000,VC01_CA_45000
TEXT:5,144,9,10,0.000000,VC01_CA_45000_PM3
TEXT:5,128,9,10,0.000000,VC02_CA_34000
TEXT:5,112,9,10,0.000000,VC02_CA_34000_PM3
TEXT:5,96,9,10,0.000000,VC02_CA_45000
TEXT:5,80,9,10,0.000000,VC02_CA_45000_PM3
TEXT:5,64,9,10,0.000000,VC03_CA_45000
TEXT:5,48,9,10,0.000000,VD01_CA_30000
TEXT:5,32,9,10,0.000000,VD01_CA_30000_PM3
- simple to train
- simple to integrate into other projects ( has dll build option )
- can recognize even words or images not just font characters
- it's not smart. You have the option to make zero bad recognitions
- so simple you can edit the code yourself for custom inputs/outputs
- it's not smart. it will never be able to recognize handwriting
- it's not optimized for speed. Though it's acceptable for small recognitions
- was made as a temp project. Was so practical I added it to git
- experiment with the value of binarization treshold. A good value is when fonts do not break into small parts and have only one version.
- clear content of the "FontLib" directory
- run the OCR on the input image
- rename all the images in the "UnrecognizedFonts" directory. If the image contains an 'a' character, name the file "a.png". If you have multiple versions of 'A', you can name the files "A 1.png", "a 2.png"....
- move all the named files into "FontLib" directory
- run OCR on the input image again. If you did well, the "UnrecognizedFonts" directory is empty now.
- edit Init.cfg, set SpaceCharacterWidth, DistanceBetweenRows values. These will depend on the size of the fonts you are using
- output should be available in "TextExtracted.txt" file
-
Q : OCR does nothing
-
A : Did you set the binarization treshold properly ? OCR will segment the input picture based on colors. If you have too many colors, it will break up characters into multiple parts
-
Q : I set binarization treshold and characters have multiple versions. "UnrecognizedFonts" directory is never empty A : Binarization treshold is probably too low. Fonts tend to have a fade out effect that blends into the background. If you do not remove this "blend" region, fonts will have multiple versions
-
Q : Sometimes my characters get merged. Why ?
-
A : Your input image probably contains compression artifacts or the content is blurry. You can try to use an external program to do some smart binarization yourself
-
Q : Can it convert smileys from messager messages ?
-
A : Yes. You can name images for example ":).png" and it will convert into text version
-
Q : 'I' is recognized as 'l' and 'o' is recognized as '0'
-
A : Tough luck, there is no way for an OCR to guess fonts that look exactly alike. But do make sure in init.cg you FontExactMatch=1


