Comments (2)
 changun
commented on July 30, 2024
changun
commented on July 30, 2024
Hi xuetf,
I realized that there is a bug in the dataset pre-processing step for
CiteULike (see commit that fixed the bug:
c127de4
)
Unfortunately, with the bug fixed, while I still see improvement over other
approaches, I were not able to achieved recall beyond 33%.
…On Mon, Dec 3, 2018 at 6:46 PM xuetf ***@***.***> wrote:
Great Approach. Besides, I am wondering what parameters you use to achieve
slightly better performance than the number reported in the paper. I change
the learning rate to 0.00 and it achieve 29% recall in the citeulike
dataset, which is lower than 33% recall reported in the paper. The
parameters is as follows. Hope for your help soon.
model = CML(n_users,
n_items,
features=dense_features,
embed_dim=200,
margin=2.0,
clip_norm=1.1,
master_learning_rate=0.001,
hidden_layer_dim=512,
dropout_rate=0.3,
feature_projection_scaling_factor=1,
feature_l2_reg=0.1,
use_rank_weight=True,
use_cov_loss=True,
cov_loss_weight=1
)
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#15>, or mute the thread
<https://github.com/notifications/unsubscribe-auth/AA1Ff5qRJNGyHgMwDZAVho_dxla-8rIEks5u1eIcgaJpZM4Y_z8w>
.
--
Cheng-Kang (Andy) Hsieh
UCLA Computer Science Ph.D. Student
M: (310) 990-4297
from collmetric.
 xuetf
commented on July 30, 2024
xuetf
commented on July 30, 2024
Hi xuetf, I realized that there is a bug in the dataset pre-processing step for CiteULike (see commit that fixed the bug: c127de4 ) Unfortunately, with the bug fixed, while I still see improvement over other approaches, I were not able to achieved recall beyond 33%.
…
On Mon, Dec 3, 2018 at 6:46 PM xuetf @.***> wrote: Great Approach. Besides, I am wondering what parameters you use to achieve slightly better performance than the number reported in the paper. I change the learning rate to 0.00 and it achieve 29% recall in the citeulike dataset, which is lower than 33% recall reported in the paper. The parameters is as follows. Hope for your help soon. model = CML(n_users, n_items, features=dense_features, embed_dim=200, margin=2.0, clip_norm=1.1, master_learning_rate=0.001, hidden_layer_dim=512, dropout_rate=0.3, feature_projection_scaling_factor=1, feature_l2_reg=0.1, use_rank_weight=True, use_cov_loss=True, cov_loss_weight=1 ) — You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub <#15>, or mute the thread https://github.com/notifications/unsubscribe-auth/AA1Ff5qRJNGyHgMwDZAVho_dxla-8rIEks5u1eIcgaJpZM4Y_z8w .
-- Cheng-Kang (Andy) Hsieh UCLA Computer Science Ph.D. Student M: (310) 990-4297
Thank you for your answering. I've found that the feature pro-processing step has the same problem as what you said for the ratings pre-processing. The first element of tag-item.dat is the number of items that have the tag. After I fix this bug, I get the expected result as what is reported in your paper, i.e., 33%. (Unfortunately, It also relies on the initialization while I haven't set the seed in advance)
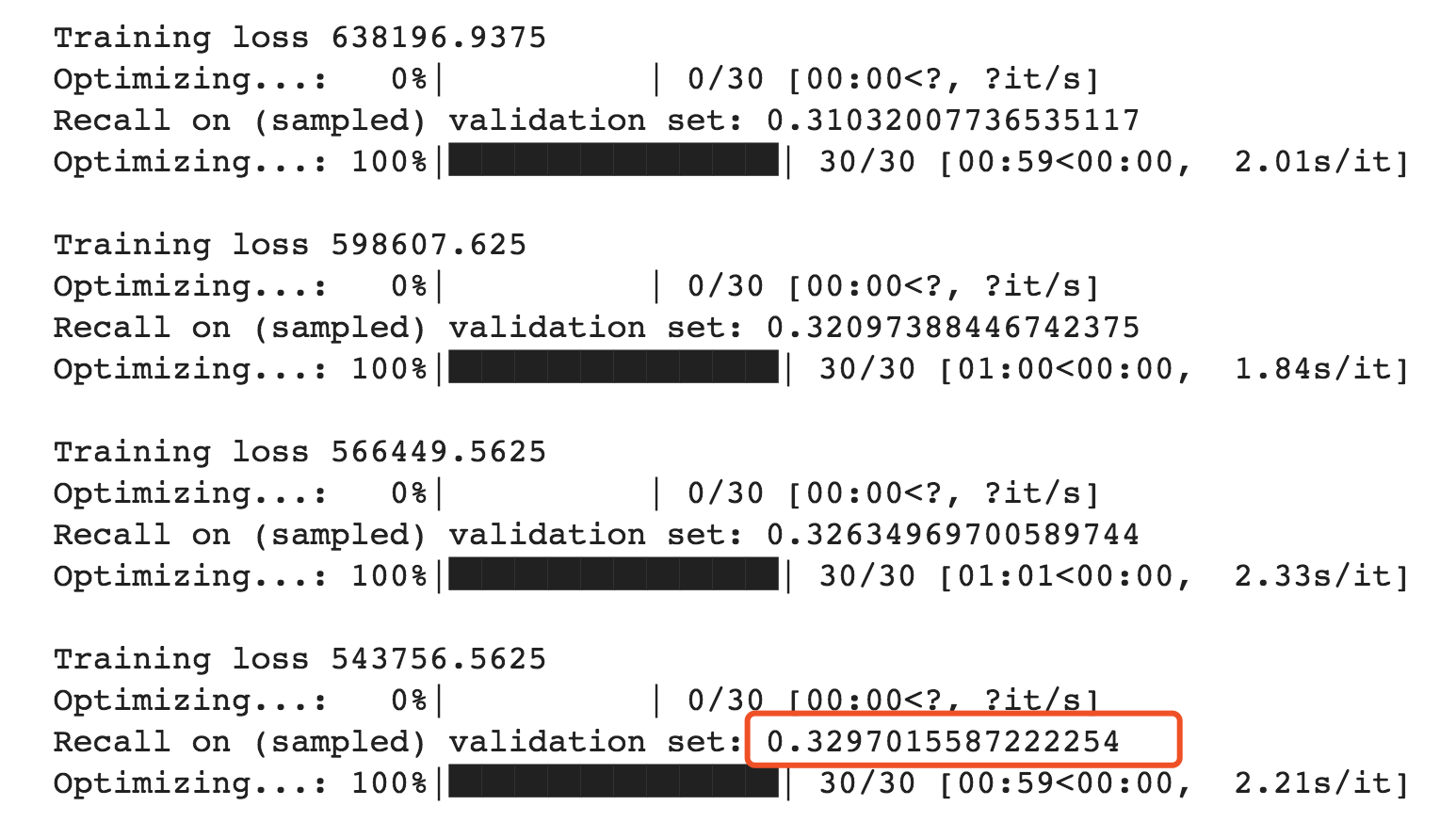
Thank you very much!
from collmetric.
Related Issues (15)
- how to work HOT 2
- Loss wouldn't decrease when training on GPU while everything is OK on CPU HOT 3
- How to save the embedding matrix on CPU instead of GPU? HOT 4
- Ignoring the user when number of items less than 5
- Validation recall is not improving during training HOT 5
- Multiprocessing queue memory release
- run your code but there is an error
- is the model code currently in the repository the same as the one you used to produce the paper results? HOT 1
- SIR
- Sir,Can you share me the original paper (CML),[email protected],thank u!
- Covariance loss is different from paper
- Is it a bug not to eliminate first element of a line in `tag-item.dat` ?
- Unsupported feed HOT 3
- Movielens 20m HOT 3
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from collmetric.